
Назад | Содержание | Вперед
Аналогично языку С++ ввод/вывод в языке Java выполняется с использованием потоков. Поток ввода/вывода - это некоторый условный канал, по которому отсылаются и получаются данные. При этом совершенно не важно, что стоит за конкретным потоком: файл, блок памяти, экран и т. д. С точки зрения программиста, поток представляет собой ленточный транспортер, на который можно последовательно помещать куски данных, а лента доставит их по назначению. Остальные детали реализации не важны. Такая концепция помогает унифицировать методы работы со всеми устройствами ввода/вывода, сводя все к методам открытия потока, его закрытия, чтения данных из потока и записи данных в него.
В 2-й версии языка Java (Java 2) реализованы 2 типа потоков: байтовые и символьные. Байтовые потоки предоставляют удобные средства для обработки, ввода и вывода байтов или других двоичных объектов. Символьные потоки используются для обработки, ввода и вывода символов или строк в кодировке Unicode. Символьный поток I/O автоматически транслирует символы между форматом Unicode и локальной кодировкой, пользовательского ПК. Первоначальная версия языка Java 1.0 не включала символьные потоки, т.е. весь ввод/вывод был байтовым. Символьные потоки были добавлены в версии Java 1.1. Для работы с символьными и байтовыми потоками в Java реализованы несколько иерархий классов. Все они сосредоточены в пакете java.io, поэтому для использования этих классов и определенных в них методов необходимо импортировать пакет java.io.
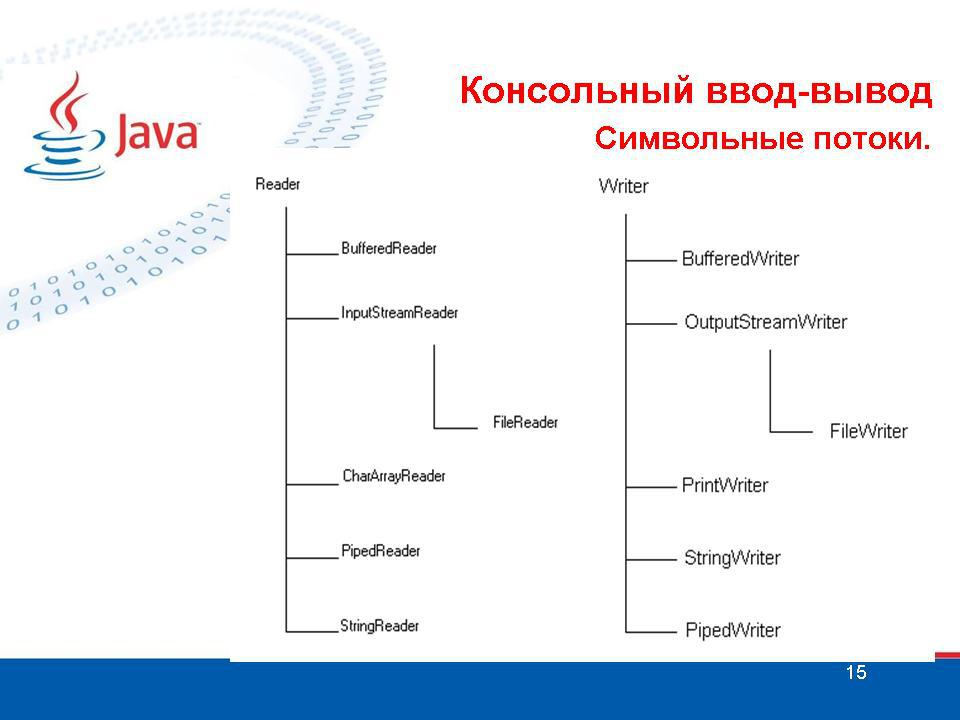
Существуют две параллельные иерархии классов ввода: для байтовых потоков (в вершине этой иерархии стоит класс InputStream) и для символьных потоков (в вершине – класс Reader). Также существуют две параллельные иерархии классов вывода: для байтовых потоков (в вершине – класс OutputStream) и для символьных потоков (в вершине – класс Writer). Иерархии Reader и Writer введены в версии Java 1.1. Кроме этих четырех иерархий есть еще класс RandomAccessFile, который объединяет как возможности ввода, так и возможности вывода, и класс File, предназначенный для работы с файловой системой на уровне выполнения системных операций, как-то: создание, удаление, переименование файлов и каталогов и т.п.
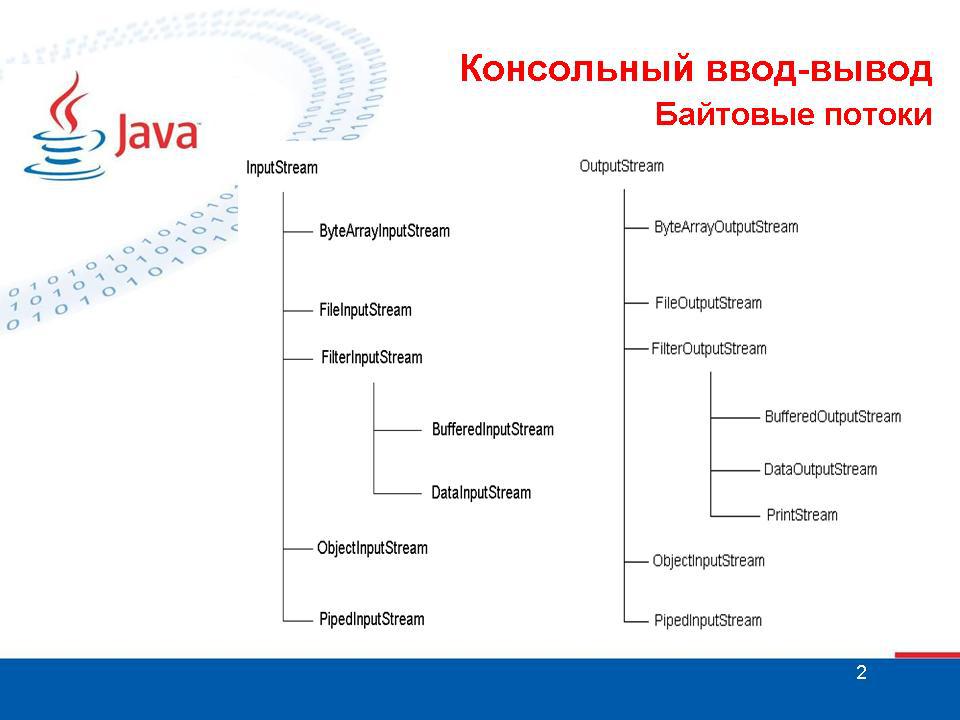

InputStream – абстрактный класс, т.е. он определяет, какие методы должны быть у всех классов данной иерархии. Кроме того, очень часто в качестве параметров конструкторов или методов различных классов выступает InputStream. Согласно правилам аппарата наследования это означает, что в качестве параметра может быть передан объект любого класса из приведенной иерархии. Это позволяет комбинировать классы для достижения нужных целей.

Это основной класс из данной иерархии для работы с файлами. Имеет два конструктора:
FileInputStream(String name) throws FileNotFoundException
FileInputStream (File file) throws FileNotFoundException
В классе FileInputStream переопределяется большая часть методов класса InputStream (в т.ч. абстрактный метод read()). Когда создается объект класса FileInputStream, он одновременно с этим открывается для чтения.

В данном примере показано, как можно читать одиночные байты, массив байтов и под-диапазон массива байтов с помощью перегруженного (и переопределенного) метода read(). В этом примере также показано, как методом available() можно узнать, сколько еще осталось непрочитанных байтов, и как с помощью метода skip() можно пропустить те байты, которые вы не хотите читать.



ByteArrayInputStream – это реализация входного потока, в котором в качестве источника используется массив типа byte. У этого класса два конструктора, каждый из которых в качестве первого параметра требует байтовый массив.
ByteArrayInputStream(byte array[ ])
ByteArrayInputStream(byte array[ ], int start, int numBytes)
Второй конструктор создает источник данных из байтового подмассива, который начинается с позиции start и имеет длину numBytes байтов.


Принципы построения иерархии OutputStream те же, что и в InputStream. Т.е. вся основная функциональность определяется абстрактным базовым классом OutputStream, а наследованные от него подклассы переопределяют абстрактный метод write() и иногда некоторые другие методы. Все методы этого класса возвращают значение void и выбрасывают в случае ошибок исключение IOException.

Класс FileOutputStream создает объект OutputStream, который можно применять для записи байтов в файл. У класса FileOutputStream есть 3 конструктора:
FileOutputStream (String filePath) throws FileNotFoundException
FileOutputStream (File fileObj) throws FileNotFoundException
FileOutputStream (String filePath, boolean append) throws FileNotFoundException
Параметры: filePath – полное имя пути файла, fileObj – объект типа File, который описывает файл. При открытии файла на запись, если файл не существует, то он создается. Если файл существует, то он будет перезаписан. Т.е. если открыть и сразу закрыть файл, то его содержимое будет потеряно, а реальный файл на диске будет нулевой длины. Исключением из предыдущего правила является последний из конструкторов. Если в нем в качестве третьего параметра (append) указать true, то файл будет открываться в режиме добавления в конец. Если файл существует, но не может быть открыт или не существует и не может быть создан, конструкторы выбрасывают исключение FileNotFoundException.


Класс ByteArrayOutputStream реализует выходной поток, в котором данные записываются в байтовый массив. У класса ByteArrayOutputStream — два конструктора. Первая форма конструктора создает байтовый массив размером 32 байта. При использовании второй формы создается байтовый массив с размером, заданным параметром конструктора:
ByteArrayOutputStream( );
ByteArrayOutputStream(int numBytes);
Данный класс содержит в дополнение к методам, унаследованным от класса Output-Stream, метод writeTo(), позволяющий записывать содержимое одного потока в другой поток
public void writeTo(OutputStream out) throws IOException









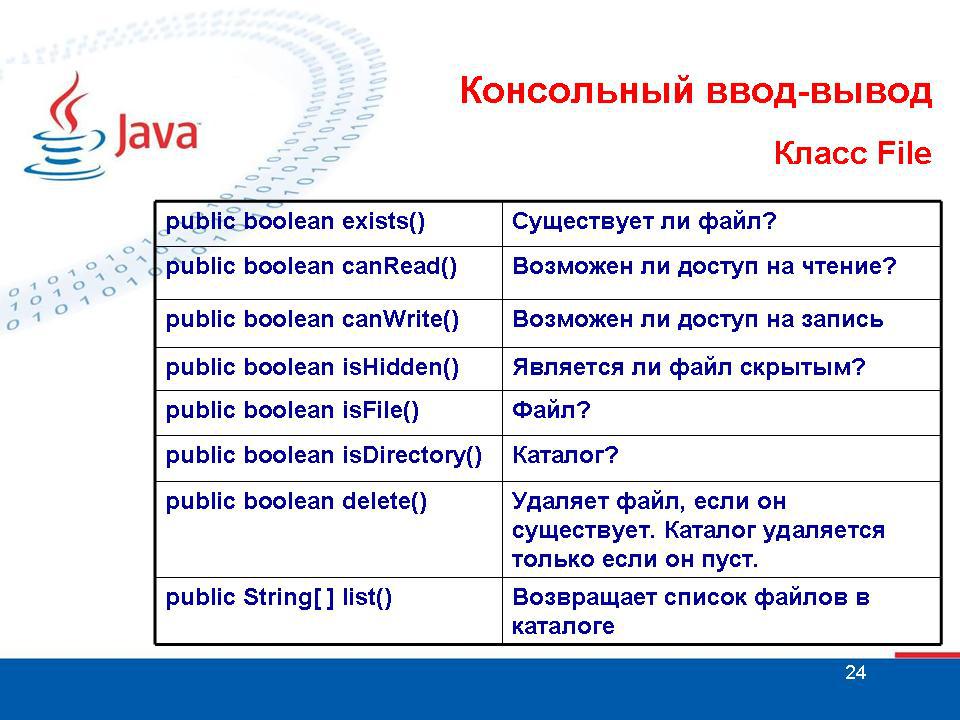
В отличие от всех прочих классов, работающих с потоками ввода/вывода, класс File работает непосредственно с файлами и каталогами операционной системы. Методы этого класса не предназначены для извлечения или сохранения информации в файлах, они управляют свойствами самого файла (такими как имя, путь, атрибуты, время создания и т.п.). Следует заметить, что каталог в Java трактуется как File-объект, имеющий одно дополнительное свойство: список имен файлов, который можно просматривать с помощью метода list().
Следует обратить внимание, что конструкторы физически не создают файл/каталог, а только пытаются получить ссылку на него. При создании экземпляра класса File реальный файл с указанным именем может не существовать. При этом он не создается при создании объекта File. Поэтому данные конструкторы не порождают IOException. В то же время после получения ссылки на файл/каталог методы класса File выполняют реальные действия с файлом (например, метод delete() физически удаляет с диска файл, на который ранее была получена ссылка). Java правильно обрабатывает разделители имен каталогов в пути, используемые в UNIX и DOS. Если вы используете стиль UNIX — символы '/', то при работе в Windows Java автоматически преобразует их в '\'. Не забудьте, если вы привыкли к разделителям, принятым в DOS, то есть, к '\', то для того, чтобы включить их в строку пути, необходимо использовать их escape-последовательности, т.е. “\\“.


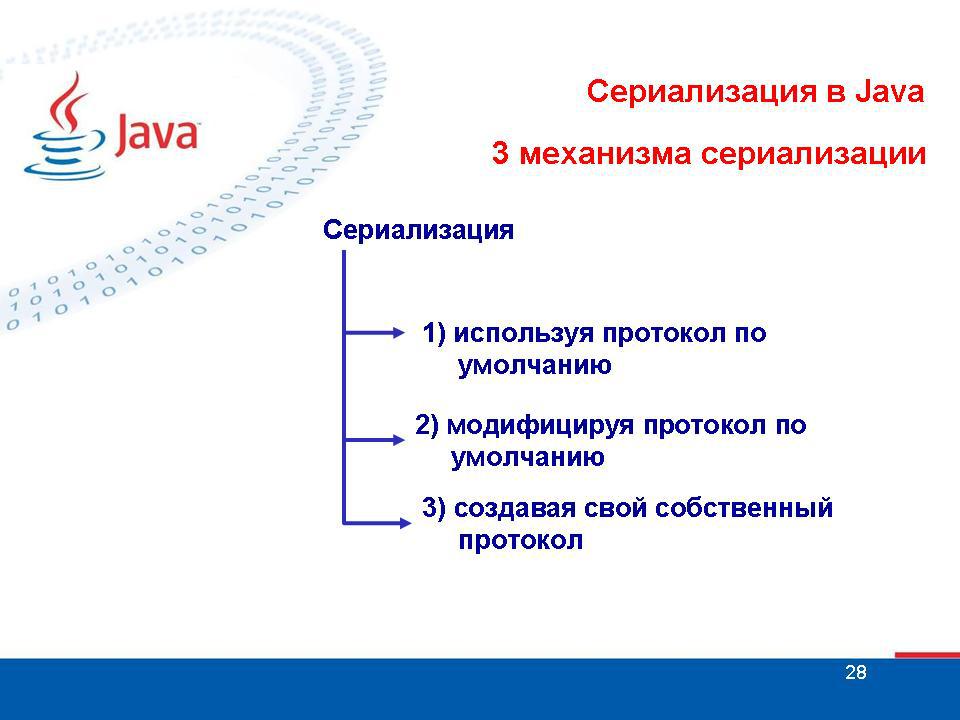
Сериализация объектов - это процесс сохранения состояния объектов в виде последовательности байтов, а также процесс восстановления в дальнейшем из этих байтов "живых" объектов. Java Serialization API предоставляет разработчикам Java стандартный механизм управления сериализацией объектов. API мал и легок в применении, а его классы и методы просты для понимания.


Для сохранения объекта в Java мы должны иметь объект, нуждающийся в сохранении и этот объект должен быть отмечен как сериализуемый. Это осуществляется путем реализации объектом интерфейса java.io.Serializable, что является для API знаком того, что объект может быть разложен на байты, а затем вновь восстановлен.

Единственное чем этот класс отличается от обычного класса - то, что он реализует интерфейс java.io.Serializable в 40-й строке. Будучи совершенно пустым, интерфейс Serializable является лишь маркерным интерфейсом - он позволяет механизму сериализации определить, может ли данный класс быть сохранен. Итак, мы можем сформулировать первое правило сериализации:
Правило №1: Сохраняемый объект должен реализовать интерфейс Serializable или унаследовать эту реализацию от вышестоящего по иерархии объекта.









Как упоминалось ранее, сохраняться могут лишь объекты, помеченные как Serializable. Класс java.lang.Object не реализует этот интерфейс, поэтому не все объекты Java могут быть автоматически сохранены. Хорошая новость заключается в том, что большая часть из них, включая AWT и компоненты Swing GUI, строки и массивы - сериализуемые.
В то же время, некоторые системные классы, такие как Thread, OutputStream и его подклассы, и Socket - не сериализуемые На самом деле даже если бы они были сериализуемыми, ничего бы не изменилось. К примеру, поток, запущенный в моей виртуальной машине, использует системную память. Его сохранение и последующее восстановление в вашей виртуальной машине ни к чему не приведет.

Другой важный момент, вытекающий из того, что java.lang.Object не реализует интерфейс Serializable, заключается в том, что любой созданный вами класс, который расширяет только Object (и больше никакие сериализуемые классы) не может быть сериализован до тех пор, пока вы сами не реализуете этот интерфейс (как было показано в предыдущем примере).
Такая ситуация вызывает проблему: что если у нас есть класс, который содержит экземпляр Thread? Можем ли мы в этом случае сохранить объект такого типа? Ответ положительный, поскольку мы имеем возможность сообщить механизму сериализации о своих намерениях, пометив объект Thread нашего класса как нерезидентный (transient).

При создании экземпляра класса PersistentAnimation создается и запускается поток animator. Мы пометили этот поток как transient, дабы сообщить механизму сериализации о том, что поле не должно сохраняться вместе с остальными состояниями этого объекта (в нашем случае, полем speed). Резюме: вы должны помечать как transient все поля, которые либо не могут быть сериализованы, либо те, которые вы не хотите сериализовать. Сериализация не заботится о модификаторах доступа, таких как private. Все резидентные поля рассматриваются как части состояния сохраняемого объекта, предназначенные для сохранения.
Следовательно нам нужно добавить еще одно правило. Итак, вот оба правила относительно сохраняемых объектов:
Правило №1: Сохраняемый объект должен реализовать интерфейс Serializable или унаследовать эту реализацию от вышестоящего по иерархии объекта.
Правило №2: Сохраняемый объект должен пометить все свои несериализуемые поля как transient.


Весь фокус в том, что виртуальная машина при вызове соответствующего метода автоматически проверяет, не были ли они объявлены в классе объекта. Виртуальная машина в любое время может вызвать privateметоды вашего класса, но другие объекты этого сделать не смогут. Таким образом обеспечивается целостность класса и нормальная работа протокол сериализации. Протокол сериализации всегда используется одинаково, путем вызова ObjectOutputStream.writeObject() или ObjectInputStream.readObject(). Таким образом, даже если в классе присутствуют эти специализированные privateметоды, сериализация объектов будет работать так же, как и для любых других вызываемых объектов.


Обратите внимание на первые строки новых private методов. Эти вызовы выполняют операции, созвучные их названию - они выполняют по умолчанию запись и чтение разложенных объектов, что важно, поскольку мы не заменяем нормальный процесс, а лишь дополняем его. Эти методы работают, потому что вызов ObjectOutputStream.writeObject() соответствует протоколу сериализации. Сначала объект проверяется на реализацию Serializable, а затем проверяется на наличие этих private методов. Если они есть, им в качестве параметра передается класс потока, через использование которого осуществляется управление кодом.
Эти private методы могут использоваться для внесения любого рода изменений в процесс сериализации. Например, для вывода объектов в поток может быть использована шифровка, а для ввода - дешифровка (при записи и чтении байтов данные записываются даже без применения технологии запутывания (obfuscation)). Методы могут использоваться также для сохранения в потоке дополнительных данных, например кода версии.



Вместо реализации интерфейсаSerializable, вы можете реализовать интерфейс Externalizable, который содержит два метода:
public void writeExternal(ObjectOutput out) throws IOException;
public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException;
Для создания собственного протокола нужно просто переопределить эти два метода. В отличие от двух рассмотренных ранее вариантов сериализации, здесь ничего не делается автоматически. Протокол полностью в ваших руках. Хотя это и наболее сложный способ, при этом он наиболее контролируемый. Возьмем, к примеру, ситуацию с альтернативным типом сериализации: запись и чтение PDF файлов Java приложением. Если вы знаете как читать и записывать PDF файлы (требуется определенная последовательность байт), вы можете создать протокол с учетом специфики PDF используя методы writeExternal и readExternal.
Так же, как и в рассмотренных случаях, нет никакой разницы в том, как используется класс, реализующий Externalizable. Вы просто вызываете методы writeObject() или readObject() и, вуаля, эти расширяемые методы будут вызываться автоматически.






Представим что мы создали класс, затем создали его экземпляр, который записали в поток объекта. Этот разложенный на байты объект какое-то время находился в файловой системе. Тем временем вы обновляете файл класса, например, добавив в него новое поле. Что произойдет если затем вы попробуете прочитать разложенный объект?
Плохая новость заключается в том, что возникнет исключительная ситуация, а именно java.io.InvalidClassException, потому что всем классам, которые могут быть сохранены, присваивается уникальный идентификатор. Если идентификатор класса не совпадает с идентификатором разложенного объекта, возникает исключительная ситуация. Однако, если задуматься над этим, зачем нужны все эти исключительные ситуации, если вы всего лишь добавили новое поле? Разве нельзя установить в поле значение по умолчанию, а после сохранено?
Да, но это потребует легких манипуляций с кодом. Идентификатор, который является частью всех классов, хранится в поле, которое называется serialVersionUID. Если вы хотите контролировать версии, вы должны вручную задать поле serialVersionUID и убедиться в том, что оно такое же, и не зависит от изменений, внесенных вами в объект. Вы можете использовать утилиту, входящую в состав JDK, которая называется serialver, чтобы посмотреть какой код будет присвоен по умолчанию (это просто hash код объекта по умолчанию).
Вот пример использования serialver с классом Baz:
> serialver Baz
> Baz: static final long serialVersionUID = 10275539472837495L;
Просто скопируйте возвращенную строку с идентификатором версии и поместите ее в ваш код. (В Windows вы можете запустить эту утилиту с опцией -show, чтобы упростить процедуру копирования и вставки). Теперь, если вы внесли какие-либо изменения в файл класса Baz, просто убедитесь что указан тот же идентификатор версии и все будет в порядке.
Контроль за версией прекрасно работает до тех пор, пока вносимые изменения совместимы. К совместимым изменениям относят добавление и удаление методов и полей. К несовместимым изменениям относят изменение иерархии объектов или прекращение реализации интерфейса Serializable. Полный перечень совместимых и несовместимых изменений приведен в Спецификации сериализации Java.
Назад | Содержание | Вперед