Рассмотренная ранее схема имеет явные перспективы к улучшению. Видно, что отдельные компоненты такого процессора срабатывают по очереди, и в момент работы, например, АЛУ память команд простаивает, ожидая следующего адреса. В то же время обычный порядок исполнения команд предполагает, что адреса будут выдаваться процессором последовательно, хотя команды переходов и вызовов подпрограмм изменяют этот порядок. Все же можно рассчитывать, что с определенной вероятностью процессор перейдет к команде из следующей ячейки памяти.
Исходя из этого, одновременно с выполнением команды в АЛУ можно выполнить чтение из следующей ячейки памяти. В этом случае, если предыдущая команда не была командой перехода, на следующем такте можно просто выполнять следующую команду. Если же в процессе выполнения команды произошел переход, следующая команда выполняться не может, и ее следует проигнорировать. Вместо этого необходимо подождать, пока из памяти команд будет считана команда, соответствующая новому адресу, на который произошел переход. Устройства процессора (в рассматриваемом примере память и АЛУ) оказались связаны в последовательную цепочку, на каждой стадии которой выполняются действия для разных команд. Такая схема представляет собой конвейер, поскольку ее работа напоминает работу сборочного конвейера – на каждой стадии производится только одна операция, но разные участки конвейера начинают обработку следующего изделия сразу же, как только завершат работу с предыдущим. На рис. 5 показана структурная схема конвейеризованного процессора. Такой процессор может выполнять каждую команду за 1 такт, если только не встретится команда, нарушающая линейную последовательность действий.
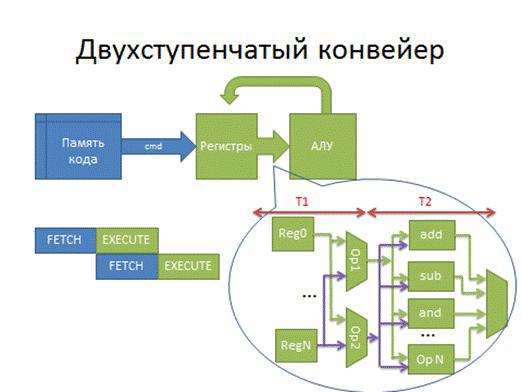
Стадии конвейера обозначены как Fetch (выборка команды) и Execute (исполнение).
Рис. 5.19 Схема конвейеризованного процессора
Данная схема при анализе ее производительности демонстрирует «узкое место». Если подробно рассмотреть взаимодействие блока регистров и АЛУ, можно увидеть, что на основе отдельных полей команды необходимо получить операнды для АЛУ. На рис. 5 они формируются мультиплексорами Op1 и Op2. Далее операнды с выходов этих мультиплексоров должны пройти через вычислительные устройства в АЛУ, а результат выполнения команды определяется другим мультиплексором, который выбирает один из возможных результатов на основе другой части команды. В итоге скорее всего окажется, что сумма времен T1 и T2 (т.е. времени T1 на формирование операндов и времени T2 на вычисление результата требуемой операции) окажется существенно больше, чем время чтения команды из памяти на первой стадии конвейера.
Для увеличения тактовой частоты можно разделить линию данных на две части, поставив регистры для сигналов Op1 и Op2. Тогда на одном и том же такте блок регистров будет формировать операнды, а в это же время АЛУ вычислять результат для операндов, переданных на предыдущем такте. Можно видеть, что данная схема также является конвейеризованной. Эффект от конвейеризации проиллюстрирован на рис. 5.20.
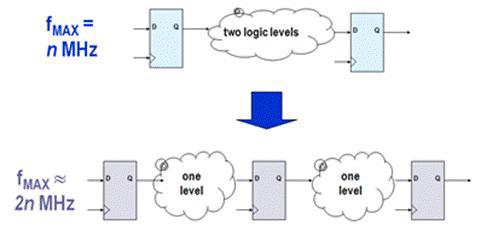
Рис. 5.20 Пояснение к эффекту от конвейеризации
После добавления регистра между регистрами процессора и АЛУ обработка команды стала производиться за 3 такта. Это проиллюстрировано на рис. 5.21.
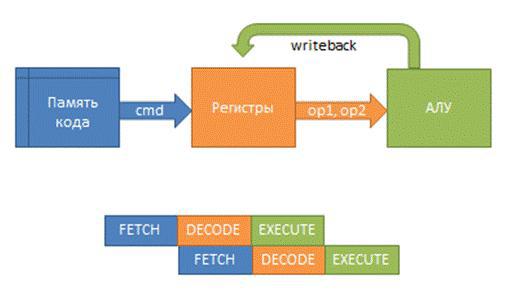
Рис. 5.21 Схема процессора с трехступенчатым конвейером
Как и в предыдущем случае, процессор одновременно выполняет несколько команд. Каждая команда последовательно проходит через стадии «выборка из памяти» (Fetch), «декодирование команды» (Decode) и «выполнение команды» (Execute). Поскольку линии для передачи данных от одного синхронного компонента другому стали короче, тактовая частота процессора в среднем возрастает по сравнению с двухступенчатым конвейером.
Следует заметить, что при нарушении линейного порядка исполнения команд задержка в исполнении составит не один, а два такта. Это является следствием того, что решение о переходе на новый адрес принимается на последней стадии конвейера, поэтому невозможно заранее определить, с какого адреса следует продолжать выборку.
Возможно провести и дальнейшее увеличение числа стадий конвейера. На рис. 5.22 показан пятиступенчатый конвейер. Например, для выполнения команды чтения из памяти можно разбить ее на следующие стадии:
1. Чтение кода команды.
2. Чтение содержимого регистров.
3. Формирование адреса памяти, из которого необходимо произвести чтение.
4. Чтение данных из внешней памяти (MemoryPhase)
5. Запись прочитанных данных в регистр процессора (Writeback)

Рис. 5.22 Схема процессора с пятиступенчатым конвейером

Рис. 5.23 Дальнейшее увеличение числа стадий конвейера
Если при исследовании процессора выяснится, что какие-то цепи являются слабым местом, можно продолжить процесс конвейеризации. Например, на рис. 5 показан процессор, в котором стадия Executeразбита на две – Execute1 и Execute2. Однако при увеличении числа стадий конвейера усложняется конечный автомат, управляющий активизацией отдельных устройств. В конечном итоге негативный эффект от увеличения задержек из-за усложнения управляющего автомата перекроет позитивный эффект от увеличения тактовой частоты в цепочке обработке данных.
При увеличении числа стадий конвейера необходимо решить еще одну проблему. Если процессор исполняет последовательно две команды, одна из которых изменяет содержимое регистра, а следующая – читает это значение, возникает т.н. «конфликт по данным». Если посмотреть на схему распределения операций по тактам, станет видно, что при последовательном чтении регистра на стадии Decode во втором случае будет прочитано все еще старое значение, потому что новое еще только формируется в АЛУ. Увеличение длины конвейера усугубляет эту ситуацию. В целом конфликты по данным, или «зависимости по данным» можно классифицировать следующим образом:
1. «Чтение после чтения» (RAR, ReadAfterRead) – разрешение конфликта не требуется. В этом случае данные в регистре после выполнения первой команды не изменяются.
2. «Чтение после записи» (RAW, ReadAfterWrite) – самая критичная зависимость по данным, заключающаяся в том, что после запуска в конвейер команды записи в регистр следует подождать, пока данные будут физически записаны в этот регистр.
3. «Записьпослечтения» (WAR, WriteAfterRead) – в этом случае следует принять меры против того, чтобы запись не произошла раньше, чем будет выполнено чтение. Это возможно, если управляющий автомат процессора организован так, чтобы обеспечивать переменную длину команд в тактах. Если какая-то команда не требует работы с памятью, для нее может не использоваться стадия MemoryPhase. Поэтому может возникнуть ситуация, когда следующая команда выполнится быстрее и успеет прочитать данные из регистра, в который еще не была физически произведена запись предыдущей командой.
4. «Запись после записи» (WAW, WriteAfterWrite) – рекомендация аналогичная предыдущему случаю.
Простейшим способом разрешения конфликтов является задержка следующей команды до исполнения предыдущей при наличии зависимостей. На первый взгляд, это отменяет эффект конвейеризации, однако задержка требуется только в том случае, если следующая команда работает с теми же регистрами, в которые производит запись предыдущая. Часто повышение эффективности работы процессора с высокой степенью конвейеризации перекладывается на компилятор.