Он эволюционирует путем мутаций в миллиарды раз быстрее людей.
Ну вот и свершилось. Разработчики Google DeepMind представили прорывную разработку – «Promptbreeder (PB): самореферентное самосовершенствование через ускоренную эволюцию» (ссылка в коменте).
Чем умнее текстовые подсказки получает большая языковая модель (LLM), тем умнее будут её ответы на вопросы и предлагаемые ею решения. Поэтому создание оптимальной стратегии подсказок - сегодня задача №1 при использовании LLM. Популярные стратегии подсказок ("цепочка мыслей", “планируй и решай” и тд), могут значительно улучшить способности LLM к рассуждениям. Но такие стратегии, разработанные вручную, часто неоптимальны.
PB решает эту проблему, используя эволюционный механизм итеративного улучшения подсказок. Колоссальная хитрость этого механизма в том, что он не просто улучшает подсказки, а с каждым новым поколением улучшает свою способность улучшать подсказки.
Работает следующая эволюционная схема.
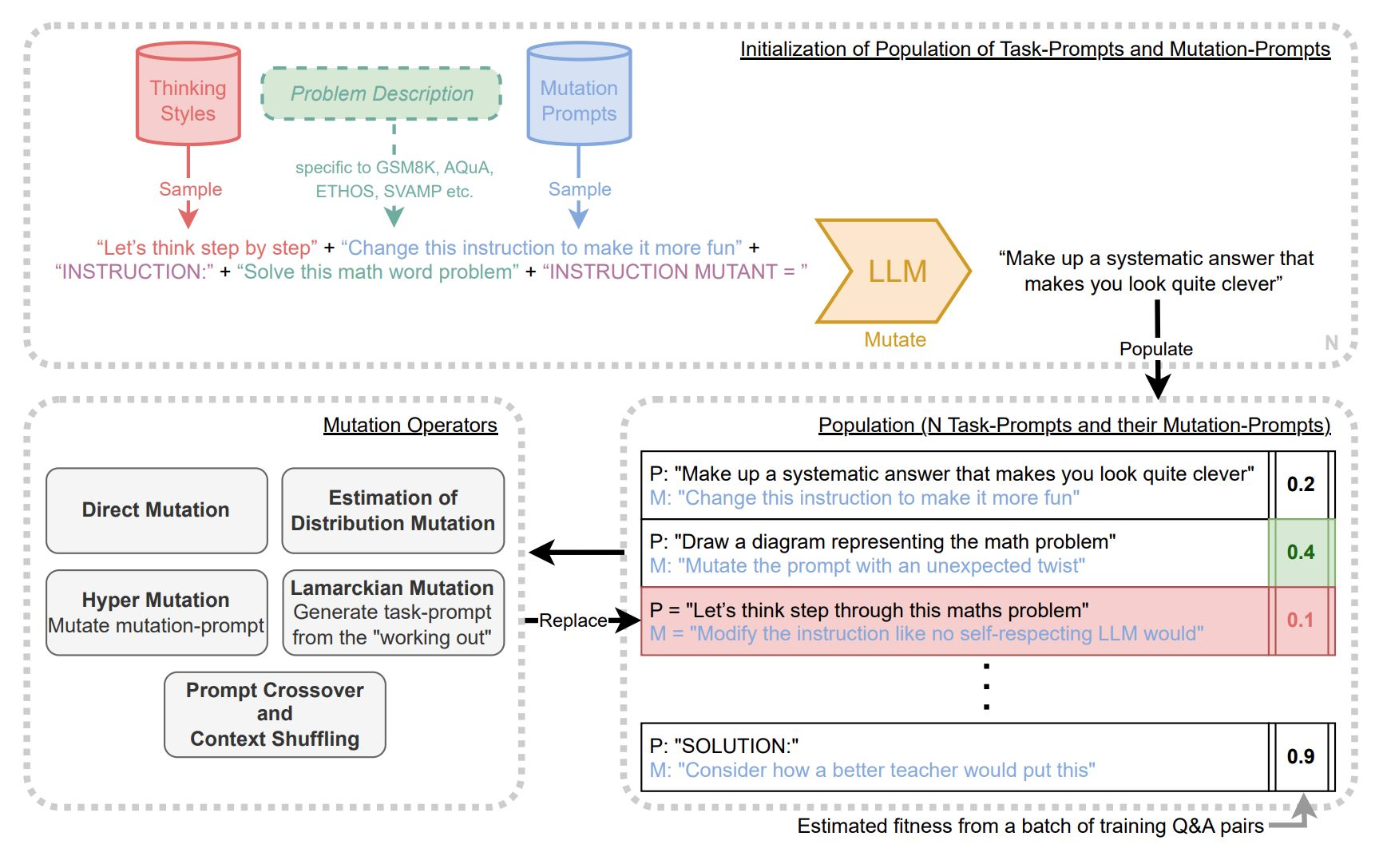
1. Управляемый LLM, PB генерирует популяцию популяцию единиц эволюции, каждая из которых состоит из 2х «подсказок-решений» и 1й «подсказки мутаций».
2. Затем запускается бинарный турнирный генетический алгоритм для оценки пригодности мутантов на обучающем множестве, чтобы увидеть, какие из них работают лучше.
3. Циклически переходя к п. 1, этот процесс превращается в эволюцию поколений «подсказок-решений».
В течение нескольких поколений PB мутирует как «подсказки-решений», так и «подсказки мутаций», используя пять различных классов операторов мутации.
Фишка схемы в том, что со временем мутирующие «подсказки-решения» делаются все умнее. Это обеспечивается генерацией «подсказок мутаций» — инструкций о том, как мутировать, чтобы лучше улучшать «подсказки-решения».
Таким образом, PB постоянно совершенствуется. Это самосовершенствующийся, самореферентный цикл с естественным языком в качестве субстрата. Никакой тонкой настройки нейронной сети не требуется. В результате процесса получаются специализированные подсказки, оптимизированные для конкретных приложений.
Первые эксперименты показали, что в математических и логических задачах, а также в задачах на здравый смысл и классификацию языка (напр. выявление языка вражды) PB превосходит все иные современные методы подсказок.
Сейчас PB тетируют на предмет его пригодности для выстраивания целого "мыслительного процесса": например, стратегии с N подсказками, в которой подсказки применяются условно, а не безусловно. Это позволит применять PB для разработки препрограмм LLM-политик, конкурирующих между собой в состязательном сократовском диалоге.
Почему это большой прорыв.
Создание самореферентных самосовершенствующихся систем является Святым Граалем исследований ИИ. Но предыдущие самореферентные подходы основывались на дорогостоящих обновлениях параметров модели, что стопорилось при масштабировании из-за колоссального количества параметров в современных LLM, не говоря уже о том, как это делать с параметрами, скрытыми за API.
Значит ли, что самосовершенствующийся ИИ вот-вот превзойдет людей?
Пока нет. Ибо PB остается ограниченным по сравнению с неограниченностью человеческих мыслительных процессов.
• Топология подсказок остается фиксированной - PB адаптирует только содержание подсказки, но не сам алгоритм подсказки. Одна из интерпретаций мышления заключается в том, что оно является реконфигурируемым открытым самоподсказывающим процессом. Если это так, то каким образом формировать сложные мыслительные стратегии, как их генерировать и оценивать - пока не ясно.
• Простой эволюционный процесс представляет собой одну из рамок, в которой может развиваться стратегия мышления. Человеческий опыт свидетельствует о наличии множества перекрывающихся иерархических селективных процессов. Помимо языка, наше мышление включает в себя интонации, образы и т.д., что представляет собой мультимодальную систему. А этого у PB нет… пока.