Временная Иерархическая Память
Концепции, Теория и Терминология
Джеф Хокинс и Дайлип Джордж, Numenta Inc.
Предисловие
Есть множество вещей, легко дающихся людям, но недоступных пока для компьютеров. Такие задачи, как распознавание визуальных паттернов, понимание естественного языка, распознавание и манипулирование объектами на ощупь и ориентирование в сложном мире, элементарны для людей. Да, несмотря на десятилетия исследований, у нас нет жизнеспособного алгоритма для реализации на компьютере этих и многих других когнитивных функций.
У человека за эти способности в основном отвечает неокортекс. Временная Иерархическая Память (Hierarchical Temporal Memory, HTM) – это технология, имитирующая структурные и алгоритмические свойства неокортекса. Следовательно, HTM дает надежду на построение машин, которые приблизятся или даже превзойдут уровень человека при выполнении многих когнитивных задач.
HTM не похожи на традиционные программируемые компьютеры. Для традиционных компьютеров программисты пишут программы, решающие конкретные проблемы. Например, одна программа может быть использована для распознавания речи, а другая, совершенно отличная от нее программа, может быть использована для моделирования погоды. С другой стороны, об HTM лучше думать, как о системе памяти. HTM не программируются и не выполняют различных алгоритмов для различных проблем. Вместо этого, HTM «учатся» решать проблему. HTM обучают путем подачи на них сенсорных данных, и способности HTM определяются в основном тем, какие данные подавались.
HTM организованы как деревовидная иерархия узлов, где каждый узел реализует общие функции обучения и памяти. HTM хранит информацию в иерархии, моделируя мир. Все объекты в мире, будь то машины, люди, здания, речь или поток информации в компьютерной сети, имеют какую-либо структуру. Эта структура иерархическая и в пространственном, и во временном отношении. HTM также иерархическая и в пространстве и во времени, и, следовательно, может эффективно фиксировать и моделировать структуру мира.
HTM похожи на Байесовские Сети; однако, они отличаются от большинства Байесовских Сетей тем, как используется время, иерархия и внимание. HTM могут быть реализованы программно на традиционном компьютерном оборудовании, но о них лучше думать, как о системах памяти.
Эта статья описывает теорию, лежащую в основе HTM, описывает, что HTM делают и как они это делают. Она детально описывает две наиболее важные способности HTM - способность обнаруживать причины и выдвигать гипотезы о причинах. Она вводит концепции, лежащие в основе двух других способностей HTM - предсказания и поведения.
Эта статья описывает теорию, лежащую в основе изделия корпорации Numenta, но не описывает само изделие. Отдельный документ описывает продукт Numenta и то, как применить технологию HTM к проблемам реального мира.
HTM основывается на биологии. Следовательно, есть детальное соответствие между HTM и биологической анатомией неокортекса. Заинтересованные читатели могут найти частичное описание этого в главе 6 в книге «On Intelligence» (Times Books, 2004). Нет необходимости знать биологические соответствия HTM для использования HTM.
Концепции в основе HTM не очень сложные, но их очень много, так что путь к ее пониманию может быть трудным. Эта статья должна быть понятна для любого достаточно заинтересованного человека. Мы не предполагаем наличия специальной математической подготовки. (Полное математическое описание алгоритма доступно при наличии лицензии). Научиться разрабатывать системы, основанные на HTM по сложности почти аналогично написанию сложной программы. Любой может научиться этому, но если вы начинаете с нуля, потребуется долго учиться.
Эта статья подразделяется на семь основных разделов, перечисленных ниже.
1. Что делает HTM?
2. Как HTM обнаруживает причины и выдвигает гипотезы о причинах?
3. Почему иерархия так важна?
4. Как каждый узел обнаруживает и выдвигает гипотезы о причинах?
5. Почему время так существенно для обучения?
6. Вопросы
7. Выводы
1. Что делает HTM?
Уже свыше 25 лет известно, что неокортекс работает по единому алгоритму; зрение, слух, осязание, язык, поведение и многое другое, выполняемое неокортексом – проявления единого алгоритма, применяемого к различным модальностям сенсорной информации. Это же верно и для HTM. Так что, когда мы описываем, что делает HTM и как она работает, наше объяснение будет в терминах, не зависящих от сенсорной модальности. Как только вы поймете, как работает HTM, вы поймете, как можно применить HTM к большому классу задач, включающему много того, что не относится к человеку.
HTM выполняет следующие четыре основных функции в независимости от конкретной задачи, к которой она применяется. Первые две обязательны, последние две опциональны.
1) Обнаружение причин в мире
2) Выдвижение гипотез о причинах нестандартной информации
3) Предсказание
4) Управление поведением
Рассмотрим эти основные функции по очереди.
1.1 Обнаружение причин в мире
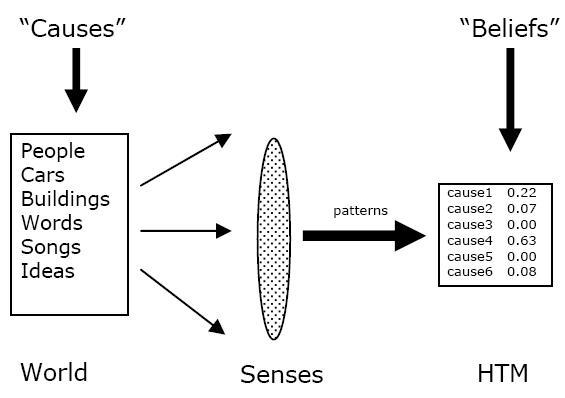
Рисунок 1 показывает, как HTM взаимодействует с внешним миром. Слева на этом рисунке прямоугольник, представляющий мир, который изучает HTM. Мир состоит из объектов и их отношений. Некоторые из объектов мира являются физическими, такие как автомобили, люди и дома. Некоторые из объектов мира могут быть не физическими, такие как мысли, слова, песни или потоки информации в сетях. Важным атрибутом объектов мира с точки зрения HTM является то, что у них постоянная структура; они существуют во времени. Мы называем объекты мира «причинами». Вы можете понять, откуда взялось это слово, если зададитесь вопросом «какова была изначальная причина паттерна на моей сетчатке» или «какова была изначальная причина звука, услышанного моими ушами». В любой момент времени в мире активна иерархия причин. Когда вы слышите устную речь, причинами звуков, поступающих в ваши уши, являются фонемы, слова, фразы и идеи. Все они одновременно активны, и все они являются правомерными причинами слуховой информации.
Рисунок 1
Мы существуем в одном большом физическом мире. Однако, определенные HTM могут быть нацелены только на подмножество этого мира. HTM может быть ограничена знанием о финансовом рынке, или взаимодействовать только с погодным феноменом, или только с геофизическими данными, демографическими данными или данными, собранными с сенсоров, установленных на автомобилях. Далее, когда мы будем ссылаться на «мир» HTM, мы будем иметь в виду его ограниченную часть, которая действует на HTM.
На правой стороне рисунка 1 изображена HTM. Она взаимодействует с ее миром через один или несколько сенсоров в средней части рисунка. Сенсоры делают выборки некоторых атрибутов мира, таких как свет или прикосновение, однако сенсоры, используемые HTM, не обязаны быть аналогичными органам чувств человека. Обычно сенсоры не обнаруживают объекты мира напрямую. У вас нет «чувства автомобиля» или «чувства слова». Вместо этого, цель HTM - обнаружить в потоке сырой информации от сенсоров то, что существуют такие объекты, как «машина» или «слово». Сенсоры обычно подают в HTM массив данных, где каждый элемент – это измерение некоторого маленького атрибута мира. У человека зрительный нерв, переносящий информацию от сетчатки в кортекс, состоит приблизительно из миллиона волокон, где каждое волокно переносит информацию об освещенности маленькой части видимого пространства. В слуховом нерве около тридцати тысяч волокон, где каждое волокно несет информацию о небольшом частотном диапазоне звукового спектра. Сенсоры, подключенные к HTM, как правило, будут организованы аналогично. То есть, информация с сенсоров будет топологически организованными наборами данных, где каждый элемент измеряет локальную и простую величину.
У всех систем HTM есть какой-либо типа сенсорной информации, даже если данные поступают из файла. С точки зрения HTM, у сенсорных данные есть две основных свойства. Первое - сенсорные данные должны измерять что-то, что прямо или косвенно связано с причинами в мире, который мог бы вас заинтересовать. Если вы хотите, чтобы HTM изучала погоду, она должна чувствовать что-то, относящееся к погоде, такое как температура и давление в различных местах. Если HTM предназначена для анализа трафика в компьютерных сетях, она могла бы измерять количество пакетов в секунду и загрузку процессоров на маршрутизаторах. Вторая – сенсорные данные должны поступать во времени непрерывным потоком, тогда как причина, лежащая в основе сенсорных данных, может оставаться относительно стабильной. Временной аспект сенсорных данных может исходить из движения или изменения объектов в реальном мире (такого, как движение автомобиля или ежеминутные флуктуации рынка ценных бумаг), или он может исходить из движения самой сенсорной системы по миру (такого, когда вы идете по комнате или проводите пальцами по объекту). В любом случае, сенсорные данные должны непрерывно изменяться во времени для того, чтоб HTM обучалась.
HTM получает пространственно-временные паттерны, приходящие от сенсоров. Поначалу у HTM нет знания о причинах в мире, но через процесс обучения, который будет описан далее, она «открывает», что является причиной. Конечной целью этого процесса является то, что в HTM образуется внутреннее представление причин в мире. В мозгу нервные клетки обучаются представлению причин в мире, например, нейроны, активизирующиеся, когда вы видите лицо. В HTM причины представляются векторами чисел. В любой момент времени, основываясь на текущей и прошлых выборках, HTM будет назначать вероятность, что в данный момент воспринимается та или иная причина. На выходе HTM выдается набор вероятностей для каждой из известных причин. Это распределение вероятностей в каждый момент называется «гипотезой». Если HTM знает о десяти причинах в мире, у нее будет десять переменных, представляющих эти причины. Значения эти переменных – гипотезы – то, что по мнению HTM происходит в мире в данный момент. Обычно HTM знает о множестве причин, и, как вы увидите, HTM в действительности изучает иерархию причин.
Обнаружение причин это сердце восприятия, творчества и интеллекта. Ученые пытаются открыть причины физических феноменов. Бизнесмены ищут причины, лежащие в основе маркетинговых или бизнес-циклов. Врачи ищут причины болезней. С момента вашего рождения ваш постепенно запоминает представления для любых вещей, с которыми вы в конечном итоге встречаетесь. Вы должны обнаружить, что автомобили, здания, слова и мысли являются постоянными структурами мира. Прежде чем вы сможете узнавать что-то, ваш мозг должен сначала обнаружить, что существуют вещи.
Все системы HTM должны пройти через фазу обучения, в которой HTM изучает, какие причины существуют в мире. Сначала все HTM изучают маленькие и простые причины их мира. Большие HTM, когда предоставлено достаточное количество сенсорных данных, могут обнаружить сложные высокоуровневые причины. При достаточном обучении и правильном дизайне должно быть возможно построить HTM, способные обнаружить причины, которые не могут обнаружить люди. После начального обучения HTM может продолжить обучение или нет, в зависимости от нужд приложения.
В обнаружении причин может быть очень большое значение. Для рыночных флуктуаций, болезней, погоды, доходов производства и отказов сложных систем, таких как энергетические сети, важно понимание высокоуровневых причин. Обнаружение причин также необходимый предшественник для второй способности HTM – выдвигать гипотезы.
1.2 Выдвижение гипотез о причинах нестандартной информации
Когда HTM знает, какие причины существуют в ее мире и как представлять их, она может выдвигать гипотезы. «Выдвижение гипотез» подобно распознаванию паттернов. При наличии нестандартной информации HTM будет «выдвигать гипотезы» о том, какая из известных причин вероятнее всего присутствует в мире в данный момент. Например, если бы у вас была система зрения, основанная на HTM, вы могли бы показать ей картинки и она могла бы выдвинуть гипотезы о том, какие объекты на картинках. Результатом было бы распределение гипотез по всем известным причинам. Если бы картинка была недвусмысленной, распределение гипотез было бы с ярко выраженным максимумом. Если бы картинка была сильно неоднозначна, распределение гипотез было бы ровным, поскольку HTM не была бы уверенной, на что она смотрит.
Текущие гипотезы HTM могут быть непосредственно считаны с системы, чтоб быть использованными где-то за пределами HTM (что не возможно для человека!). Иначе, текущие гипотезы могут быть использованы HTM для того, чтоб делать предсказания или генерировать поведение.
В большинстве систем HTM сенсорная информация всегда будет новой. В системе зрения, подсоединенной к камере, мог бы быть миллион пикселей сенсорной информации. Если камера будет смотреть на сцены из реального мира, маловероятно, что один и тот же паттерн попадет в HTM дважды. Таким образом, HTM должна манипулировать с новой информацией и при выдвижении гипотез, и во время обучения. Фактически, у HTM нет отдельного режима, в котором бы она выдвигала гипотезы. HTM всегда выдвигает гипотезы о причинах, даже в процессе обучения (даже если трудно выдвинуть гипотезу, прежде чем будет пройдено достаточно длительное обучение). Как упоминалось ранее, существует возможность запретить способность к обучению по окончании процесса обучения с сохранением способности выдвигать гипотезы.
Большинству приложений HTM будут требоваться изменяющиеся во времени сенсорные данные для того, чтоб выдвигать гипотезы, хотя некоторым – нет. Это зависит от природы сенсоров и причин. Мы можем увидеть эти различия и у человека. Наши органы слуха и осязания без временной компоненты не могут выдвинуть гипотезу практически ни о чем. Мы должны проводить руками над объектами, чтобы выдвинуть гипотезу о том, чего же они касаются. Аналогично, статический звук передает очень мало информации. Со зрением ситуация двойственная. В отличие от ситуации с осязанием и слухом, люди могут распознавать изображения (то есть выдвигать гипотезы о причинах), когда изображение мелькает перед ними и глаза не успевают сдвинуться. Таким образом, визуальные гипотезы не всегда требуют изменяющейся во времени информации. Однако, в нормальном визуальном процессе мы двигаем глазами, движется наше тело и объекты в мире также движутся. Так что идентификация статических, мелькающих картинок – это специальный случай, возможный из-за статистических свойств зрения. В общем случае, даже в случае зрения, выдвижение гипотез происходит на изменяющейся во времени информации.
Хотя иногда возможно выдвижение гипотез на статических сенсорных паттернах, теория, лежащая в основе HTM показывает, что невозможно обнаружить причины, не имея непрерывно изменяющейся информации. Таким образом, все системы HTM, даже те, которые выдвигают гипотезы на статических паттернах, должны обучаться на изменяющейся во времени информации. Недостаточно просто изменяющейся сенсорной информации, для этого было бы достаточно последовательности некоррелирующих паттернов. Обучение требует, чтобы в процессе поступления изменяющихся паттернов причина оставалась неизменной. Например, когда вы проводите пальцами по яблоку, хотя тактильная информация постоянно изменяется, исходная причина – яблоко – остается неизменной. Это же верно и для зрения. Когда ваши глаза сканируют яблоко, паттерны на сетчатке изменяются, но исходная причина остается неизменной. И снова, HTM не ограничены человеческими типами сенсоров: они могли бы изучать изменение рыночных данных, изменение погоды и динамику трафика в компьютерных сетях.
Выдвижение гипотез о нестандартной информации является очень существенным. Есть множество задач распознавания паттернов, которые кажутся человеку простыми, но которых существующие компьютеры не могут решить. HTM может решать такие задачи быстро и точно, точно также как человек. В дополнение есть множество задач по выдвижению гипотез, которые трудны для человека, но которые системы HTM могли бы решить.
1.3 Предсказания
HTM состоят из иерархии узлов памяти, где каждый узел изучает причины и формирует гипотезы. Часть алгоритма обучения, выполняемая каждым узлом, заключается в том, чтобы хранить возможные последовательности паттернов. Комбинируя память о возможных последовательностях с поступающей информацией, каждый узел может совершать предсказания того, что вероятно должно произойти дальше. HTM в целом, как набор узлов, также делает предсказания. Точно также, как HTM может выдвигать гипотезы о причинах нестандартной информации, она также может предсказывать новые события. Предсказание будущих событий – это суть творчества и планирования. Оставив на потом детали того, как это работает, сейчас мы можем утверждать, для чего может быть использовано предсказание. Есть несколько применений для предсказаний HTM, включая установку предпочтений, воображение и планирование, а также генерацию поведения. Сейчас самое время сказать несколько слов об этих применениях.
Установка предпочтений
Когда HTM предсказывает, что вероятнее всего должно произойти далее, предсказание может выступать в качестве того, что называется «априорная вероятность», обозначая, что оно склоняет систему выдвигать гипотезы по предсказанным причинам. Например, если HTM будет обрабатывать текст или устную речь, он мог бы автоматически предсказывать, какие звуки, слова и мысли скорее всего возникнут далее. Это предсказание помогает системе понимать зашумленные или недостающие данные. Если возникает звуковая неоднозначность, HTM будет интерпретировать звук, основываясь на том, что ожидается.
В случае HTM у нас есть возможность вручную установить априорные вероятности в дополнение к априорным вероятностям, установленным через предсказание. То есть, мы можем вручную сказать HTM, чтобы она ожидала или искала определенные причины или набор причин, таким образом реализуя направленный поиск.
Воображение и планирование
HTM автоматически предсказывает и предчувствует, что вероятнее всего произойдет далее. Вместо того, чтоб использовать эти предсказания для установки предпочтений, предсказания HTM могут быть направлены обратно в HTM, замещая сенсорные данные. Именно этот процесс происходит, когда люди думают. Размышление, воображение и планирование будущего, мысленный разговор в голове – все это одно и то же, и достигается путем серии предсказаний. HTM так же могут делать это. Воображение будущего может быть значимо для многих приложений. Например, предположим, что автомобиль оборудован HTM для мониторинга близлежащего дорожного движения. Если возникает новая ситуация, HTM может выполнить серию предсказаний, чтобы увидеть, какие события вероятнее всего произойдут в будущем, и, следовательно, может вообразить опасные ситуации прежде, чем они возникнут.
Предсказание также является сердцем того, как HTM может направлять моторное поведение, четвертой и последней способности HTM.
1.4 Управление поведением
HTM, изучившая причины в мире и то, как эти причины ведут себя во времени, по существу создала модель этого мира. Теперь предположим, что HTM подключена к системе, которая физически взаимодействует с миром. Вы можете вообразить HTM, подключенную к роботу, но не обязательно ограничиваться этим. Важно то, что система может перемещать ее сенсоры в ее мире и/или манипулировать объектами в ее мире. В такой системе HTM обучается генерировать сложное целенаправленное поведение. Здесь будет дано краткое объяснение.
На рисунке 2а изображена система с HTM и способностью генерировать простое поведение. Моторные компоненты этой системы имеют встроенное «рефлексивное», или предустановленное поведение. Это простое поведение, существующее независимо от HTM
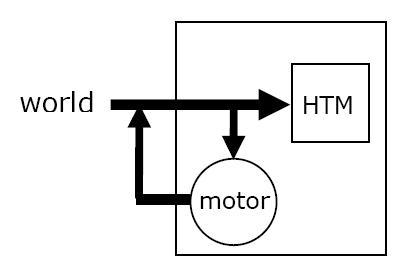
Рисунок 2а
HTM моделирует мир путем построения представлений причин, включая предустановленное моторное поведение
По мере того, как HTM открывает причины в ее мире, она обучается представлять ее предустановленное поведение точно также, как и поведение объектов внешнего мира. С точки зрения HTM, система, к которой она подключена, всего лишь еще одним объектом мира. HTM формирует представление о поведении системы, к которой она подключена, и, что важно, она учится предсказывать ее поведение. Затем, с помощью механизма ассоциативной памяти представление встроенного поведения в HTM связывается с механизмом, создающим встроенное движение (рисунок 2b). После такого ассоциативного связывания, когда HTM задействует внутреннее представление движения, она может вызвать возникновение движения. Если HTM предсказывает, что движение возникнет, она может сделать так, что движение произойдет заранее. Теперь HTM находится в положении управления движением. Связывая вместе последовательности этих простых движений, она может создавать новое сложное целенаправленное поведение. Чтобы сделать это, HTM выполняет те же самые шаги, что она выполняла, когда генерировала связку предсказаний и воображалу будущее. Однако, теперь, вместо простого воображения будущего, HTM связывает встроенные движения, делая их действительно происходящими.
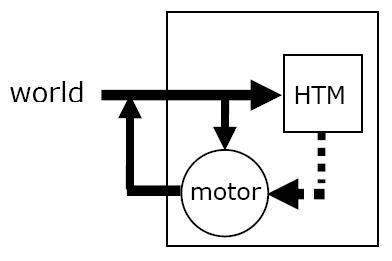
Рисунок 2b
Представление моторного поведения автоассоциативно сопоставляется с моторными генераторами, позволяющими HTM управлять поведением
Вы можете наблюдать основы этого механизма изучения поведения на своем собственном теле. Такое поведение, как движение глаз, жевание, дыхание, отдергивание руки от острых предметов, ходьба и даже бег в основном генерируются в старых частях мозга, не в неокортексе. Большую часть времени эти движения генерируются с минимальным или вообще без участия неокортекса. Например, вы обычно не осознаете того, как ваши челюсти и язык двигаются во время жевания, как ваши ноги двигаются при ходьбе и обычно вы не осознаете процесс дыхания. Однако, вы можете сознательно контролировать необычным способом ваше дыхание, движение глаз или ходьбу. Когда вы делаете это, управление осуществляется вашим неокортексом. Когда вы родились, неокортекс не знал, как делать это. Он должен изучить это таким образом, как только что было описано.
HTM могут управлять поведением множества различных типов систем; они не ограничены традиционной робототехникой. Вообразите офисное здание с кондиционированием. На каждом этаже осуществляется отдельное управление температурой. Теперь мы присоединяем HTM к зданию. Данные, поступающие в HTM, идут от датчиков температуры по всему зданию, а также от настроек температуры. HTM могла бы также получать данные, представляющие время дня, количество людей, входящих и выходящих из здания, текущие погодные условия снаружи, и т.д. По мере обучения HTM строит модель здания, которая включает то, как управление температурой ведет себя по отношению к другим вещам, происходящим в здании и вокруг него. Не имеет значения, люди изменяют настройки или другие компьютеры. HTM теперь использует эту модель для предсказания того, когда произойдут какие либо события, включая то, когда включается или выключается управление температурой или когда ее повышают или понижают. Связывая внутренние представления этих действий с температурным контролем, HTM может начать управлять «поведением» здания. HTM может лучше предчувствовать всплески потребления, и, следовательно, лучше управлять желаемой температурой или сокращать потребление энергии.
Выводы
Мы кратко обсудили четыре способности HTM:
1) Обнаружение причин в мире
2) Выдвижение гипотез о причинах нестандартной информации
3) Предсказание
4) Использование предсказаний для управления моторным поведением.
Это фундаментальные способности, которые могут быть применены к многим типам задач. Теперь мы обратим наше внимание на то, как HTM в действительности обнаруживают причины и выдвигают о них гипотезы.
2. Как HTM открывают причины и выдвигают о них гипотезы?
HTM структурно устроены как иерархия узлов, где каждый узел выполняет один и тот же алгоритм. На рисунке 3 изображена простая иерархия HTM. Сенсорные данные поступают снизу. Сверху выходит вектор, в котором каждый элемент представляет потенциальную причину сенсорных данных. Каждый узел иерархии выполняет ту же функцию, что и вся иерархия целиком. То есть, каждый узел рассматривает пространственно-временные паттерны, поступающие в него и обучается назначать причины поступающим в него паттернам. Проще говоря, каждый узел в независимости от его места в иерархии открывает причины своей входной информации.
Выход каждого узла одного уровня становится входом следующего уровня иерархии. Самые нижние узлы иерархии получают информацию от маленьких участков сенсорной области. Следовательно, причины, которые он открывает, соотносятся с маленькими участками входного сенсорной области. Вышестоящие области получают информацию от многочисленных нижестоящих узлов, и снова открывают причины этой информации. Эти причины промежуточной сложности, возникающие на участках большего размера. Узел или узлы на верхушке иерархии представляют высокоуровневые причины, которые могут возникать в любой части сенсорного поля. Например, в HTM, выдвигающей визуальные гипотезы, узлы внизу иерархии обычно обнаруживают простые причины, такие как края, линии и углы на маленькой части визуального поля. Узлы на верхушке иерархии будут представлять сложные причины, такие как собаки, лица, автомобили, которые могут появиться на всем визуальном пространстве или на любой части визуального пространства. Узлы промежуточных уровней иерархии представляют причины промежуточной сложности, которые возникают на участках промежуточного размера. Помните, что все эти причины должны быть обнаружены HTM. Они не программируются и не выбираются разработчиком.
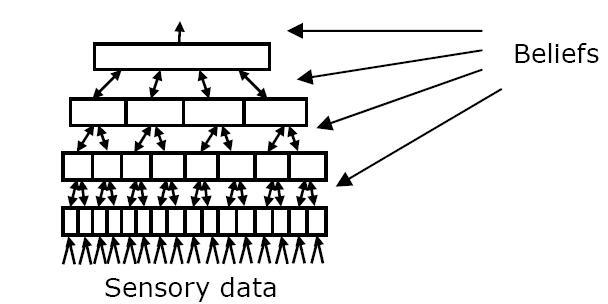
Рисунок 3
В HTM гипотезы существуют на всех уровнях иерархии, не только на верхнем уровне. Гипотеза – это внутреннее состояние каждого узла. Вы можете рассматривать ее как вектор чисел, каждое из которых представляет вероятность того, что причина активна.
Каждый элемент в векторе гипотезы (то есть каждая причина) зависит сам от себя. Каждая причина может быть понята и интерпретирована сама по себе и имеет свое собственное значение. Другими словами, значение переменной, представляющей причину, не зависит от того, какие другие причины могут быть активными в том же самом векторе. Это не значит, что причины, представляемые узлом, статистически независимы, или что только одна из них активна за раз. Несколько причин могут быть активными одновременно. Представления, используемые в HTM, отличаются от тех, которые, скажем, используются в ASCII коде. Конкретный бит из восьми битов ASCII кода не имеет значения сам по себе.
Выход узла – также вектор. Выход аналогичен гипотезам узла, и наследуется от вектора гипотез. Сейчас пока мы будем рассматривать выход узла как его гипотезы. Хотя это не совсем корректно, так будет проще описывать операции в HTM.
Держа это в уме, мы можем сказать, что информация на входе узла – это гипотезы дочерних узлов. Выход узла это гипотезы, которые станут частью информации, поступающей на вход родителя. Даже будет корректным рассматривать информацию от сенсоров как гипотезы, приходящие от сенсорной системы.
В идеальном мире не было бы никакой однозначности на каждом узле. Однако, на практике такого не бывает. Одним из важных свойств HTM является то, что она быстро разрешает конфликт или неоднозначность входной информации по мере ее продвижения вверх по иерархии.
Каждый узел HTM имеет обычно фиксированное количество причин и фиксированное количество выходных переменных. Следовательно, HTM начинает с фиксированного количества возможных причин, и, в процессе тренировки она обучается присваивать им смысл. Узлы не «добавляют» причины по мере открытия, вместо этого, в процессе обучения, смысл выходных переменных постепенно изменяется. Это происходит на всех уровнях иерархии одновременно. Следствием такой методики обучения является то, что необученная HTM не может формировать осмысленных представлений на вершине иерархии до тех пор, пока узлы на нижнем уровне не пройдут достаточное обучение.
Базовые операции в каждом узле делятся на два шага. Первый шаг – связать входной паттерн узла с одной из множества точек квантования (представляющих обобщенные пространственные паттерны входной информации). Если у узла есть 100 точек квантования, узел назначает каждой из 100 точек квантования вероятность того, что текущая входная информация соответствует точке квантования. Снова, на этом первом шаге, узел определяет, насколько близко к каждой из точек квантования текущий входной паттерн, и назначает вероятность каждой точке квантования.
На втором шаге узел ищет обобщенные последовательности этих точек квантования. Узел представляет каждую последовательность переменной. По мере поступления паттернов во времени, узел назначает этим переменным вероятность, что текущая входная информация является частью каждой из последовательностей. Набор этих переменных для последовательностей является выходом узла и передается вверх по иерархии родительскому(им) узлу(ам).
Узел также может посылать информацию своим детям. Сообщение, идущее вниз по иерархии, представляет распределение по точкам квантования, тогда как сообщение, идущее вверх по иерархии, представляет распределение по последовательностям. Следовательно, по мере продвижения информации вверх по иерархии каждый узел пытается слить серию входных паттернов в относительно стабильный выходной паттерн. По мере продвижения информации вниз по иерархии каждый узел принимает относительно стабильные паттерны от своих родителей и пытается обратить в последовательности пространственных паттернов.
Путем сопоставления причин последовательностям паттернов происходит естественное слияние времени по мере продвижения паттерна вверх по иерархии. Быстро изменяющиеся низкоуровневые паттерны становятся медленно изменяющимися по мере их продвижения вверх. Обратное также верно. Относительно стабильные паттерны на верхушке иерархии может развернуться в сложную временную последовательность паттернов внизу иерархии. Изменяющиеся паттерны, поступающие на вход узла, аналогичны сериям музыкальных нот. Последовательности этих нот подобны мелодиям. Если входной поток, поступающий на узел, соответствует одной из запомненных им мелодий, узел передает «название» мелодии вверх по иерархии, а не отдельные ноты. Следующий вышестоящий узел делает то же самое, рассматривая последовательности последовательностей, и т.д. Каждый узел предсказывает, какая нота или ноты вероятнее всего должны последовать далее, и эти предсказания передаются вниз по иерархии дочерним узлам.
Количество уровней иерархии, количество узлов на каждом уровне иерархии и емкость каждого узла не критичны для основных положений теории HTM. Аналогично, точные соединения между узлами не критичны, пока между каждыми двумя узлами сохраняют ясные отношения отцы/дети в иерархии. Рисунок 4 показывает несколько вариаций соединений, которые правомерны в HTM. Дизайн и емкость конкретных HTM должна соответствовать поставленной задаче и доступным вычислительным ресурсам. Большая часть усилий может уйти на получение оптимальной производительности. Однако, любые конфигурации HTM будут работать в какой-либо степени. В этом отношении система надежна.
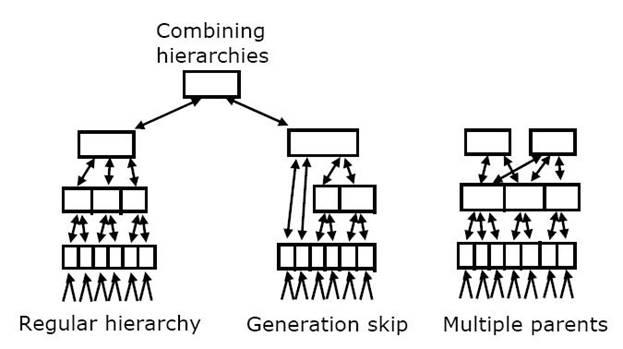
Рисунок 4
Исходя из того, что каждый узел HTM должен открывать причины и выдвигать о них гипотезы (точно то же самое, что делает HTM целиком, только в меньшем масштабе), мы придем к двум вопросам. Первый, почему так важна иерархия? То есть, почему проще открывать причины и выдвигать гипотезы, используя иерархию узлов? Второй, как каждый узел открывает причины и выдвигает гипотезы? В конце концов, каждый узел должен решать ту же самую задачу, что и вся система в целом. Далее мы обратимся к первому из этих двух вопросов.
3. Почему иерархия так важна?
Есть четыре причины, почему так важно использовать иерархию узлов. Мы затронем каждую из них, начиная с наиболее важной.
3.1 Совместное использование представлений ведет к обобщению и эффективности хранения
Большинство методов, предложенных для распознавания паттернов, не способны масштабироваться к большой задаче. Часто эти методы безуспешны, потому что количество памяти и времени, требуемого для обучения, растет экспоненциально по мере роста пространства задачи, что делает непрактичным построение больших систем. HTM могут потребовать долгого обучения и много памяти, но они не требуют экспоненциального роста. Иерархия в HTM является ключом к их способности масштабироваться. Причины на нижних уровнях иерархии распределяются по высокоуровневым причинам, значительно сокращая количество времени и памяти, требуемых для обучения новым причинам, и обеспечивая HTM средствами к обобщению предыдущего опыта к новым и нестандартным причинам.
Чтобы помочь вам понять, почему HTM может решать задачи, недоступные другим алгоритмам, мы взглянем более глубоко на затруднения, имеющиеся у этих других подходов. Будем использовать распознавание визуальных паттернов как пример задачи, потому что эта проблема подверглась длительному изучению и знакома многим исследователям. Но помните, алгоритм HTM и его исходы, которые мы обсудим, не являются специфическими для зрения.
Наиболее основным подходом, используемым для распознавания объектов на визуальном изображении – это хранение представления-прототипа для каждого из объектов, которые должны распознаваться. Неизвестные паттерны затем проходят через набор трансформаций для приведения их в соответствие с прототипом. Назовем это методом «прототипа и трансформации». Например, если вы хотите распознать печатные буквы, вы могли бы хранить изображение-прототип для каждой буквы. Взяв неизвестное изображение, вы сначала преобразовали бы неизвестное изображение в координатах x-y, чтобы отцентрировать его. Затем вы выполнили бы масштабирующее преобразование, чтобы привести к размеру прототипа. Потом вы могли бы повернуть неизвестное изображение. В конце концов, вы использовали бы некоторую метрику между трансформированным изображением и прототипом для определения наилучшего соответствия. Этот подход может работать на простых задачах, таких как распознавание печатных символов, но он быстро терпит неудачу на более сложных задачах. Для большинства объектов реального мира вы не можете идентифицировать «прототип». Количество возможных преобразований почти не ограничено, и часто не находится известных преобразований, которые могли бы быть выполнены для приведения изображения к прототипу.
Например, вообразите, что вы пытаетесь распознать изображение собаки. На вашем прототипе собака повернута влево, а на неизвестном изображении – вправо (конечно, вы не знаете этого, поскольку изображение неизвестное). Вы могли бы испробовать над неизвестным изображением трансформацию «вращение в плоскости», и теперь она бы смотрела бы влево. Однако, что если бы у вас было две картинки, одна с датским догом, другая с китайским мопсом? Человек мог бы узнать обе эти собаки, но какой тип преобразования мог бы быть использован для приведения одного представления к другому? Это сложно сказать. Еще хуже, что если одна картинка показывает собаку спереди, а другая – сзади? Человек не испытывал бы трудностей, распознавая на обеих картинках собаку, но в этом случае не существует обычного преобразования, которое могло бы привести изображение сзади к изображению спереди. Специалисты по зрению испробовали множество способов для преодоления этой проблемы. В конце концов они пришли к выводу, что необходимо хранить более одного прототипа для каждого объекта. Возможно, им понадобились бы прототипы для различных пород собак и каждая – под различными углами.
Сколько различных образцов объектов понадобится? Если бы вы могли хранить изображение каждой собаки, которую вы когда-либо видели, то предположительно было бы легче распознать на неизвестном изображении собаку путем сравнения с любыми виденными ранее изображениями. Конечно, это бесполезно. Во-первых, количество изображений, которые могли бы понадобиться для каждого объекта, виртуально не ограничено, и, во-вторых, вам все равно необходимо было бы выполнять некоторые преобразования и применять метрику для сравнения нестандартных объектов с множеством ранее виденных прототипов. Системы, пытающиеся хранить множество прототипов слишком долго обучаются и требуют очень много памяти. Следовательно, все методы вышеописанного типа работают только на простых задачах. При применении к изображениям реального мира они терпят неудачу. Сегодня общая задача визуального распознавания остается нерешенной.
HTM могут выдвигать визуальные гипотезы в широком масштабе при использовании разумного количества памяти и процессорного времени. HTM не выполняют никаких трансформаций как часть процесса выдвижения гипотез. Визуальные системы, построенные с использованием HTM, не вращают, не сдвигают, не масштабируют и не выполняют никаких других преобразований над неизвестным изображением для получения «соответствия» прототипу. Более того, визуальные системы HTM даже не хранят прототипов в обычном смысле. HTM пытаются сопоставить поступающую информацию ранее виденным паттернам, но они это делают по частям за раз и в иерархическом порядке.
Чтобы увидеть, как это происходит, давайте начнем с того, что вообразим один узел внизу иерархии, узел, смотрящий на маленькую часть визуального поля. Если этот узел смотрел бы на кусочек изображения 10x10 (100 двоичных пикселей), количество возможных паттернов, которое он мог бы увидеть, составляет 2 в 100й степени, это очень большое число. Даже если узел видел только крошечную долю возможных паттернов, он не смог бы хранить каждый паттерн, который он предположительно видел бы за свою жизнь. Вместо этого, узел хранит ограниченное, фиксированное число паттернов, скажем 50 или 100. Эти сохраненные паттерны являются точками квантования. Вы можете рассматривать точки квантования как наиболее общие паттерны из тех, что узел видел за время обучения. Дальнейшее обучение не может увеличить число точек квантования, но оно может изменить сами точки. В каждый момент узел получает новую и нестандартную информацию и определяет, насколько близка она к каждой из точек квантования. Заметьте, что этот низкоуровневый узел не знает ничего о больших объектах, таких как собаки и автомобили, поскольку кусок 10х10 пикселей – это всего лишь маленькая часть большого объекта. Причины, которые этот узел может открыть, ограничены по количеству и по сложности. Обычно в визуальной системе причины, открытые узлами, находящимися внизу иерархии, соответствуют таким причинам, как края и углы. Эти причины могут быть частью большинства различных высокоуровневых причин. Край может быть частью собаки, кошки или автомобиля. Следовательно память, используемая для хранения и распознавания низкоуровневых причин, будет использоваться совместно многими высокоуровневыми причинами.
Узел уровнем выше по иерархии получает в качестве входной информации выходную информацию всех своих дочерних узлов. (Предположим, что выход узла – это просто распределение по точкам квантования, игнорируя пока роль памяти последовательностей). Этот узел второго уровня назначает точки квантования большинству обычно возникающих совпадений низкоуровневых причин. Это означает, что узел второго уровня может обучиться представлять только те причины, которые являются комбинациями причин более низкого уровня. Это ограничение применяется снова и снова по мере продвижения вверх по иерархии. Дизайн таков, что совместное использование представлений в иерархии дает нам экспоненциальный выигрыш по памяти. Отрицательной стороной такого ограничения является то, что систему сложно обучить распознавать новые объекты, не составленные из ранее запомненных подобъектов. Это ограничение является редко создает проблему, потому что новые объекты в мире обычно сформированы из комбинации ранее изученных подобъектов.
Хотя совместное использование представлений в иерархии делает возможным выдвижение гипотез, HTM все равно может потреблять много памяти. Вернемся к примеру с распознавание собаки, ориентированной налево или направо. Для того, чтобы визуальная система, основанная на HTM, распознавала обе картинки (то есть, присваивала им одну и ту же причину), ей необходимо демонстрировать собак или подобных животных, ориентированных и налево и направо (и по многим другим направлениям). Это требование не делает различий на нижних уровнях иерархии, но это означает, что на средних и высшем уровне HTM должна хранить множество различных комбинаций низкоуровневых объектов и назначать им одну и ту же причину. Следовательно, HTM использует много памяти, но иерархия гарантирует, что потребуется память конечного и приемлемого размера.
После достаточного начального обучения, большинство новых процессов обучения будет возникать на более высоких уровнях иерархии HTM. Вообразите, что у вас есть HTM, обученная распознавать различных животных визуально. Теперь мы представляем новый тип животного и просим HTM научиться распознавать его. У нового животного многие атрибуты такие же, как и у ранее виденных животных. У него могут быть глаза, уши, хвост, ноги, мех или чешуя. Детали нового животного, такие как глаза, похожи или идентичны ранее виденным деталям и не требуют обучения им заново. Другой пример, представим, что когда вы изучаете новое слово, вам нет необходимости изучать новые буквы, слоги или фонемы. Это существенно сокращает и память и время, требуемое на обучение распознаванию новых объектов.
Когда новая HTM обучается с нуля, низкоуровневые узлы обретают стабильность раньше высокоуровневых, отражая общие подсвойства причин в мире. Как разработчик HTM, вы можете запретить обучение низкоуровневых узлов после того, как они станут стабильны, таким образом сокращая полное время обучения данной системы. Если на HTM действует новый объект, не виденный ранее низкоуровневыми структурами, HTM потребуется гораздо больше времени для того, чтоб научиться распознавать его. Мы можем увидеть эту особенность в поведении человека. Изучить новые слова на знакомом вам языке относительно легко. Однако, если вы пытаетесь выучить новое слово иностранного языка, в котором незнакомые вам звуки и фонемы, это покажется вам трудным и займет больше времени.
Совместное использование представлений в иерархии также ведет к обобщению ожидаемого поведения. При рассмотрении нового животного, если вы видите рот и зубы, вы автоматически ожидаете, что это животное использует рот для еды и может укусить вас. Это ожидание может не казаться неожиданным, но оно иллюстрирует возможности подпричин в иерархии. Новый объект мира наследует известное поведение его субкомпонентов.
3.2 Иерархия HTM соответствует пространственной и временной иерархии реального мира
Одна из причин, по которой HTM эффективны при обнаружении новых причин и выдвижении гипотез, заключается в том, что структура мира иерархична. Вообразите две точки в визуальном пространстве. Мы можем спросить, как коррелирует освещенность этих двух точек. Если точки достаточно близки друг к другу, то их значения будут сильно коррелировать. Однако, если две точки визуально далеко друг от друга, будет сложно найти корреляции между ними. HTM использует эту структуру, сперва отыскивая явные корреляции в сенсорных данных. По мере подъема по иерархии, HTM продолжает этот процесс, но теперь она отыскивает явные корреляции причин с первого уровня, затем явные корреляции причин второго уровня, и так далее.
Объекты в мире и паттерны, создаваемые ими в сенсорных массивах, в основном имеют иерархическую структуру, которая может быть использована иерархией HTM. У тела есть основные части, такие как голова, торс, руки и ноги. Каждый из этих компонентов состоит из более мелких частей. У головы есть волосы, глаза, нос, рот, уши и т.д. Каждый из них состоит из еще более мелких частей. У глаза есть ресницы, зрачок, радужка и веки. На каждом уровне иерархии субкомпоненты близки друг к другу в паттерне, приходящем с более низких уровней иерархии.
Заметьте, что если бы вы произвольно перемешали пикселы с камеры, то визуальная система HTM не смогла бы больше работать. Она не смогла бы обнаруживать причины в мире, поскольку она не смогла бы находить сперва локальные корреляции в поступающей информации.
HTM не просто используют иерархическую пространственную структуру мира. Они так же используют иерархическую временную структуру. Узлы внизу иерархии HTM находят временные корреляции в паттернах, возникающих относительно близко и в пространстве и во времени: «паттерн B следует непосредственно после паттерна A». Поскольку каждый узел преобразует последовательность пространственных паттернов в постоянное значение, следующий уровень иерархии ищет последовательности последовательностей. Мир иерархичен не только пространственно, но и во временном смысле. Например, язык это иерархически структурированная временная последовательность. Простые звуки комбинируются в фонемы, фонемы комбинируются в слова, слова комбинируются в фразы и идеи. Временная иерархическая структура языка может быть очевидной, но даже зрение структурировано подобным образом, по крайней мере для систем, которые могут двигаться относительно мира. Визуальные паттерны, которые следуют последовательно во времени, вероятно коррелируют. Менее вероятно, что паттерны, поступающие далеко друг от друга во времени, коррелируют, но возможно, что корреляция все равно есть при взгляде на более высокоуровневые причины.
Большинство обстановок реального мира, такие как рынок, дорожное движение, биохимические реакции, человеческие отношения, язык, галактики и т.д. имеют и временную и пространственную структуру по своей природе. Эта структура – естественный результат законов физики, где силы природы тем сильнее, чем ближе объекты во времени и пространстве.
Таким образом, HTM работают потому что в мире есть пространственные и временные иерархически организованные корреляции. Корреляции сначала находятся в близком соседстве (в пространстве и времени). Каждый узел иерархии объединяет и пространственную и временную информацию, и, следовательно, по мере продвижения информации вверх по иерархии HTM, представления покрывают все большие области сенсорного пространства и все большие периоды времени.
При разработке систем HTM для определенных задач важно задаться вопросом, имеет пространство задачи (и соответствующие сенсорные данные) иерархическую структуру. Например, если вы хотите, чтобы HTM понимала финансовый рынок, вы могли бы захотеть предоставлять такие данные HTM, где смежные сенсорные данные вероятнее всего были бы скоррелированы в пространстве и во времени. Возможно это означало бы первоначальное группирование биржевых курсов по категориям, и затем по индустриальным сегментам. (То есть, технологические направления, такие как полупроводники, коммуникация и биотехнология были бы сгруппированы вместе на первом уровне. На следующем уровне технологические группы комбинировались бы с промышленными, финансовыми и другими группами). Вы могли бы построить аналогичную иерархию для облигаций, и затем на самом верху скомбинировать акции и облигации.
Вот еще пример. Предположим, вы хотите, чтобы HTM моделировала производственный бизнес. Внизу иерархии могли бы быть узлы, получающие на входе различные производственные параметры. Другой набор узлов внизу иерархии мог бы получать на входе маркетинговые параметры и параметры продаж, а также еще один набор низкоуровневых узлов мог бы получать на входе финансовые параметры. HTM скорее всего в первую очередь находила бы корреляции между производственными параметрами, чем между стоимостью рекламных услуг и доходами производственной линии. Однако, на более высоких уровнях иерархии узлы могли бы научиться представлять причины, глобальные для бизнеса, охватывающие производство и маркетинг. Дизайн иерархии HTM должен был бы отражать наиболее вероятные корреляции ее мира.
Этот принцип отображения иерархии HTM на иерархические структуры мира применяется ко всем системам HTM.
Интересный вопрос – могут ли HTM получать на входе информацию, не имеющую пространственной иерархии? Например, могли бы HTM получать на входе информацию, напрямую представляющую слова, в противовес визуальной информации от напечатанных букв? Просто слова не имеют очевидной пространственной структуры. Как бы мы организовали словарный вход в сенсорном массиве, где каждая входная линия представляет различное слово, так чтоб могли быть найдены локальные пространственные корреляции? Мы еще не знаем ответа на этот вопрос, но мы подозреваем, что HTM могут работать с такой информацией. Интуитивно кажется, что сенсорное пространство могло бы иметь только временную иерархическую организацию, хотя в большинстве случаев имеет обе. Аргументом для этого предположения является то, что на вершине иерархии больше не имеете пространственной ориентации, например, на вершине визуальной иерархии. Но выход этого верхнего узла может быть входом для узла, комбинирующего верхние визуальные и слуховые гипотезы. Выше некоторой точки иерархии уже нет ясного пространственного отображения, в представлениях нет топографии. Биологический мозг решает такую задачу, полагаю, HTM так же должны уметь.
Сенсорные данные могут быть упорядочены более чем в двух измерениях. Человеческое зрение и осязание упорядочены в двух измерениях, потому что сетчатка и кожа являются двумерными сенсорными массивами и неокортекс также имеет соответствующую двумерную организацию. Но предположим, что мы хотим иметь HTM, изучающую океан. Мы могли бы создать трехмерный сенсорный массив путем размещения датчиков температуры и течений на различных глубинах для каждой широты и долготы. Такое упорядочивание создает трехмерный сенсорный массив. Важно, что мы ожидали бы обнаружить локальные корреляции в сенсорных данных по мере продвижения по любому из этих трех измерений. Теперь мы могли бы разработать HTM, где каждый узел первого уровня получал бы данные с трехмерного кубического элемента океана. Следующий уровень иерархии получал бы информацию от низкоуровневых узлов, представляя кубический элемент большего размера и т.д. Такая система была бы хороша для обнаружения причин и выдвижения гипотез, чем система, где сенсорные данные были бы свалены в двумерный массив, как в видеокамере. Люди часто испытывают трудности при интерпретации данных высокой размерности и нам приходится создавать инструменты для визуализации, помогающие нам в таких вещах. HTM могут быть разработаны, чтобы «видеть» и «думать» в трех измерениях.
Нет причины, по которой мы должны были бы остановиться на трех измерениях. Есть математические и физические задачи, решаемые в четырех или более измерениях, и некоторые из повседневных феноменов, такие как структура бизнеса, могли бы быть проанализированы, как задачи в многомерных пространствах. Большинство из причин, которые люди ощущают через двумерные органы чувств, могли бы более эффективно анализироваться через многомерно организованные HTM. Многомерные HTM – это широкое поле для изучения.
Некоторые архитектуры HTM будут эффективнее других на определенных задачах. HTM, способные обнаруживать больше причин на низком уровне иерархии будут эффективнее и лучше при обнаружении высокоуровневых причин. Разработчики некоторых систем HTM будут тратить время на экспериментирование в различными иерархиями и организациями сенсорных массивов, пытаясь оптимизировать и производительность системы, и ее способность к обнаружению высокоуровневых причин. HTM очень работоспособны; любая разумная конфигурация будет работать, то есть, находить причины, но производительность HTM и ее способность находить высокоуровневые причины будут определяться иерархическим дизайном от узла к узлу, тем, что представляют в HTM сенсорные данные, и тем, как сенсорные данные организованы относительно низкоуровневых узлов.
Таким образом, HTM работают в основном из-за того, что их иерархический дизайн улавливает иерархическую структуру мира. Следовательно, ключевые предпосылки при разработке систем, основанных на HTM:
1) Понять, имеет ли пространство задачи соответствующую пространственно-временную структуру.
2) Убедиться, что сенсорные данные организованы так, чтоб в первую очередь обнаруживать локальные корреляции в пространстве задачи.
3) Разработать иерархию для наиболее эффективного использования иерархической структуры в пространстве задачи.
3.3 Распространение гипотез гарантирует, что все узлы быстро приходят к наилучшим взаимно согласованным гипотезам
Граф, где каждый узел представляет гипотезу или набор гипотез, обычно называют Байесовской сетью. Соответственно, HTM подобны Байесовским сетям. В Байесовских сетях гипотезы в каждом узле могут модифицировать гипотезы в других узлах, если два узла соединены таблицей условных вероятностей (CPT, Conditional Probability Table). CPT это матрица, где столбцы матрицы соответствуют отдельным гипотезам от одного узла, а строки соответствуют отдельным гипотезам другого узла. Умножая вектор, представляющий гипотезы в исходном узле, на матрицу CPT, получают вектор гипотез целевого узла.
Проиллюстрируем идею простым примером. Предположим, что у нас есть два узла, где узел A представляет гипотезу о температуре воздуха, и имеет пять переменных, помеченных «горячий», «теплый», «умеренный», «холодный» и «морозный». Узел B представляет гипотезу о выпадении осадков и имеет четыре переменных, помеченных «ясно», «дождь», «мокрый снег», «снег». Если нам что-то известно о температуре, можно что-то сказать о выпадении осадков и наоборот. Матрица CPT инкапсулирует эти знания. Довольно легко заполнить значения в CPT путем сопоставления значений в узлах A и B по мере их изменения во времени. Обучение CPT и после выдвижение гипотез о том, как знания в одном узле влияют на другой узел, может быть выполнено даже когда гипотезы двух узлов неоднозначны или при наличии распределения гипотез. Например, узел A может иметь гипотезу, что вероятность «горячий» - 0%, вероятность «теплый» - 0%, вероятность «умеренный» - 20%, вероятность «холодный» - 60% и вероятность «морозный» - 20%. Умножая этот вектор температурных гипотез на CPT даст в результате вектор, представляющий соответствующие гипотезы о выпадении осадков.
Распространение Гипотез (РГ) это математическая техника, используемая в Байесовских сетях. Если сеть узлов удовлетворяет определенным правилам, таким как отсутствие любых петель, РГ может быть использовано для того, чтоб заставить сеть быстро урегулировать набор взаимно соответствующих наборов гипотез. При соответствующих ограничениях РГ показывает, что сеть достигает оптимального состояния за время, требуемое сообщению для преодоления максимальной длины пути по сети. РГ не итерируется для достижения конечного состояния; оно происходит за один проход. Если вы устанавливаете набор гипотез на одном или более узлах Байесовской сети, РГ быстро заставит все узлы сети достигнуть взаимно соответствующих гипотез.
Для разработчика систем, основанных на HTM, полезно иметь базовое понимание Байесовских сетей и Распространения Гипотез. Исчерпывающее введение выходит за пределы этого документа, но легко может быть найдено в интернете или в книгах.
HTM использует вариант Распространения Гипотез для выдвижения гипотез. Сенсорные данные устанавливают набор гипотез на самом нижнем уровне иерархии HTM, и со временем гипотезы распространяются на высшие уровни, каждый узел в системе представляет гипотезу, взаимно соответствующую всем другим узлам. Узлы самого высшего уровня показывают, какие причины верхнего уровня наиболее соответствуют информации на нижних уровнях.
Есть несколько преимуществ при выдвижении гипотез таким образом. Одно заключается в том, что неоднозначности разрешаются по мере продвижения гипотез вверх по иерархии. Например, вообразите сеть с тремя узлами, родительским узлом и двумя дочерними. Дочерний узел A содержит гипотезы, что с 80%-й вероятностью он видит собаку и с 20%-й вероятностью он видит кошку. Дочерний узел B содержит гипотезы, что он с 80%-й вероятностью слышит поросячий визг и с 20%-й вероятностью кошачье мяуканье. Родительский узел с высокой уверенностью делает вывод, что имеется кошка, а не собака и не поросенок. Он выбирает кошку, потому что эта гипотеза единственная, которая удовлетворяет входной вероятности. Он сделал бы этот выбор, даже если изображение «кошка» и звук «кошка» были бы не самыми вероятными гипотезами дочерних узлов.
Другое преимущество иерархического РГ заключается в том, что возможно заставить систему быстро приходить в равновесие. Время, требуемое HTM для выдвижения гипотезы растет линейно с увеличением количества уровней иерархии. Однако память, требуемая HTM, растет экспоненциально с увеличением количества уровней. HTM могут иметь миллионы узлов, сохраняя при этом самый длинный путь коротким, скажем, пять или десять шагов.
Мы уже видели, что многие типы предсказания, такие как слуховое и осязательное, требуют изменяющихся во времени паттернов. Поскольку распространение гипотез не имеет дела с изменяющимися во времени данными, для выдвижения гипотез в этих модальностях должна быть добавлена концепция времени. Оказывается, что время также необходимо для самообучения сети, даже для таких задач, как распознавание статических изображений, которое на первый взгляд не требует времени. Необходимость введения времени будет объяснена детально позднее. В сеть HTM необходимо подавать изменяющиеся во времени данные, и она должна хранить последовательности паттернов для того, чтоб обучаться и выдвигать гипотезы.
HTM и Байесовские сети – это «графические вероятностные модели». Вы можете представлять HTM аналогичными Байесовским сетям, но с некоторой значительной добавкой для манипулирования временем, самообучения и обнаружения причин.
РГ имеет несколько ограничений, которые не хотелось бы переносить на HTM. Одно уже было упомянуто. Для гарантии того, что система не зациклится бесконечно и не будет формировать ложных гипотез, РГ запрещает петли в сети. Но очевидно, что РГ работает для многих типов сетей, даже с петлями. Мы уверены, что это верно для HTM. В типичной HTM каждый узел посылает сообщения с гипотезами многим другим узлам (сильно разветвляясь) и получает сообщения с гипотезами от множества других узлов. Высокая степень разветвленности сокращает вероятность самоусиления ложных гипотез. Узлы в HTM еще более сложные, чем при обычном РГ. Из-за слияния и распространения времязависимых последовательностей простая петля между несколькими узлами практически не может привести к ложным гипотезам.
РГ очень мощная концепция и ключевая часть работы HTM. Вы должны рассматривать HTM как большие Байесовские сети, постоянно передающие гипотезы между узлами для достижения наиболее взаимно совместимых гипотез. На узлы внизу иерархии действуют в основном сенсорные паттерны, передаваемые вверх по иерархии.
В HTM все узлы являются динамическими элементами. Каждый узел может использовать свою внутреннюю память на последовательности в комбинации с информацией о последнем состоянии для предсказания того, какой должна быть следующая гипотеза, и передает эти ожидания вниз по иерархии. По существу, каждый узел динамически изменяет свое состоянии, основываясь на своей внутренней памяти. Так что изменения могут возникнуть в любом месте сети, но только в сенсорных узлах. Другое, почему узлы HTM являются динамическими, это то, что смысл их гипотез изменяется в процессе обучения; по мере открытия причин смысл выходных переменных в узлах изменяется. Это в свою очередь изменяет входную информацию к родительским и дочерним узлам, которые также должны быть подстроены.
Таким образом, в HTM есть три источника динамических изменений. Одни возникают из-за изменения сенсорной информации. Другие возникают по мере того, как каждый узел использует свою память последовательностей для предсказания того, что произойдет далее и передает эти предсказания вниз по иерархии. Третьи возникают только в процессе обучения и в более медленных временных масштабах. По мере обучения узлов, они изменяют смысл своих выходных переменных, что влияет на другие узлы, которые также должны научиться подстраивать смысл своих переменных. При любом изменении состояния сети, из-за сенсорных изменений или из-за внутреннего предсказания, сеть быстро приходит к набору наиболее взаимно совместимых гипотез. В человеческих терминах, то, что возникает в наших мыслях, иногда вызывается нашими органами чувств, иногда – нашими внутренними предсказаниями.
3.4 Иерархическое представление дает механизм внимания.
Иерархия в HTM обеспечивает механизм скрытого внимания. «Скрытое» внимание - это когда вы мысленно обращаете внимание на ограниченную порцию сенсорной информации. Люди могут обращать внимание на часть визуальной сцены. Мы можем ограничить наше восприятие областью переменного размера в центре визуального поля, и мы даже можем обращать внимание на объекты за пределами центра визуального поля. Аналогично мы можем обращать внимание на тактильную информацию от одной руки, другой руки или от языка.
Сравните это со «скрытым» вниманием, которое возникает, когда ваши глаза, пальцы или тело обращает внимание на различные объекты. Множество перцептивных систем нуждаются в средствах для скрытого внимания, хотя бы по причине необходимости обращать внимание на различные объекты в сложной сцене.
Рисунок 5 иллюстрирует базовый механизм, с помощью которого HTM реализуют скрытое внимание. Каждый узел в иерархии посылает свои гипотезы другим узлам выше по иерархии. Эти соединения иллюстрируются маленькими стрелками. Обеспечивая средства для включения и выключения этих путей, мы можем достигнуть эффекта ограничения того, что воспринимает HTM. Рисунок 5 не показывает переключающего механизма, но на нем выделены активные соединения и узлы. Гипотеза наверху иерархии будет представлять причину ограниченной части сенсорного пространства.
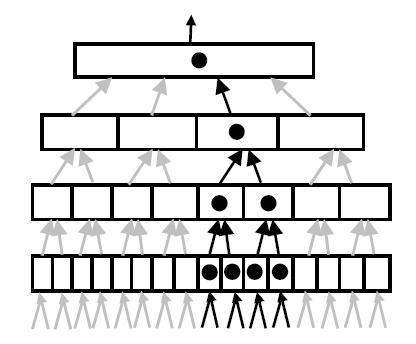
Рисунок 5
Есть несколько возможных способов активации таких переключений. В настоящий момент мы проверили, что основные принципы работают. Биологи полагают, что есть несколько способов, как это может быть, включая метод снизу вверх, где сильные неожиданные паттерны открывают путь для внимания, и метод сверху вниз, приводимый в действие ожиданиями. Более того, кажется, что в человеческом мозге часть путей, идущих вверх по иерархии, переключаемы, а часть – нет. Для HTM были разработаны и протестированы методы переключения скрытого внимания.
В этой секции мы рассмотрели большинство причин, почему для HTM существенен иерархический дизайн.
1) Совместное использование представлений сокращает требования к памяти и время на обучение.
2) Иерархическая структура мира (в пространстве и времени) отражается иерархической структурой HTM.
3) РГ-подобные методики гарантируют быстрое достижение взаимно совместимых наборов гипотез сетью.
4) Иерархия предоставляет простой механизм для скрытого внимания.
Теперь мы готовы обратить наше внимание на то, как работает отдельные узлы HTM. Вспомните, что каждый узел должен обнаруживать причины и выдвигать гипотезы. Как только мы рассмотрим, что и как делают узлы, нам станет понятно, как HTM в целом обнаруживает причины и выдвигает гипотезы о причинах нестандартной информации.
4. Как каждый узел обнаруживает и выдвигает гипотезы о причинах?
Узел HTM не «знает», что он делает. Он не знает, представляет ли получаемая информация свет, сигналы сонара, экономические данные, слова или данные производственного процесса. Узел также не знает, где он располагается в иерархии. Так как же он может самообучаться тому, какие причины ответственны за его входную информацию? В теории ответ прост, но на практике он сложнее.
Вспомните, что «причина» - это всего лишь постоянная или повторяющаяся структура в мире. Таким образом пытается назначить причины повторяющимся паттернам в его входном потоке. Есть два основных типа паттернов, пространственные и временные. Предположим, у узла есть сотня входов, и два из этих входов, i1 и i2 стали активными одновременно. Если это происходит достаточно часто (гораздо чаще, чем просто случайно), то мы можем предположить, что у i1 и i2 общая причина. Это просто здравый смысл. Если вещи часто возникают вместе, мы можем предположить, что у них общая причина где-то в мире. Другие обобщенные пространственные паттерны могли бы включать несколько причин, возникающих вместе. Скажем, узел идентифицирует пятьдесят обобщенных пространственных паттернов, найденных во входной информации. (Не нужно да и невозможно пересчитать «все» пространственные паттерны, полученные узлом). Когда приходит новый и нестандартный паттерн, узел определяет, насколько близко новый паттерн к ранее изученным 50 паттернам. Узел назначает вероятности, что новый паттерн соответствует каждому из 50 известных паттернов. Эти пространственные паттерны являются точками квантования, которые обсуждались ранее.
Давайте пометим изученные пространственные паттерны от sp1 до sp50. Предположим, узел наблюдает, что с течением времени sp4 чаще всего следует за sp7, и это происходит гораздо чаще, чем может позволить случай. Затем узел может предположить, что временной паттерн sp7-sp4 имеет общую причину. Это также здравый смысл. Если паттерны постоянно следуют один за другим во времени, то они вероятнее всего разделяют общую причину где-то в мире. Предположим, узел хранит 100 обобщенных временных последовательностей. Вероятность того, что каждая из этих последовательностей активна – это выходная информация этого узла. Эти 100 последовательностей представляют 100 причин, изученных этим узлом.
Вот что делают узлы в HTM. В каждый момент времени узел смотрит на входную информацию и назначает вероятность того, что эта входная информация соответствует каждому элементу из множества чаще всего возникающих пространственных паттернов. Затем узел берет это распределение вероятностей и комбинирует его с предыдущим состоянием, чтобы назначить вероятность того, что текущая информация на входе является частью множества чаще всего возникающих временных последовательностей. Распределение по множеству последовательностей является выходной информацией узла и передается вверх по иерархии. В конечном счете, если узел продолжает обучаться, то он мог бы модифицировать множество сохраненных пространственных и временных паттернов для того, чтоб наиболее точно отражать новую информацию.
Давайте взглянем для иллюстрации на простой пример из зрительной системы. Рисунок 6 показывает входные паттерны, которые узел мог бы ранее видеть на первом уровне гипотетической визуальной HTM. Этот узел имеет 16 входов, представляющих клочок двоичной картинки 4х4 пиксела. Рисунок показывает несколько возможных паттернов, которые могли бы появиться на этом клочке пикселей. Некоторые их этих паттернов наиболее вероятны, чем другие. Вы можете видеть, что паттерны, которые могли бы быть частью линии или угла будут более вероятными, чем паттерны, выглядящие случайно. Однако, узел не знает, что он смотрин на клочок 4х4 пиксела и не имеет встроенных знаний о том, какие паттерны встречаются чаще и что они могли бы «обозначать». Все, что он видит – это 16 входов, которые могут принимать значения между 0 и 1. Он смотрит на свои входы в течение некоторого промежутка времени и пытается определить, каике паттерны наиболее часто встречаются. Он хранит представления для обобщенных паттернов. Разработчик HTM назначает количество пространственных паттернов или точек квантования, которые данный узел может представлять.
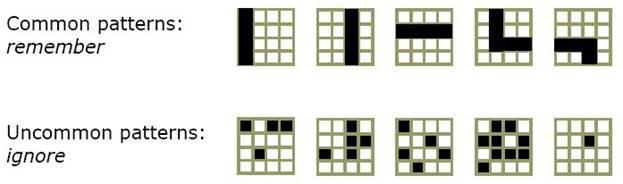
Рисунок 6a
Рисунок 6b показывает три последовательности пространственных паттернов, которые могли бы видеть низкоуровневые визуальные узлы. Первые две строки паттернов являются последовательностями, которые будут вероятнее всего чаще встречаемыми. Вы можете видеть, что они представляют линию, движущуюся слева направо и угол, двигающийся левого верхнего угла в правый нижний. Третья строка это последовательность паттернов, которая маловероятно попадалась узлу. И снова, у узла нет способа узнать, ни то, какие последовательности наиболее вероятны, ни то, что они могли бы обозначать. Все, что он может сделать – это попытаться запомнить наиболее часто встречающиеся последовательности.
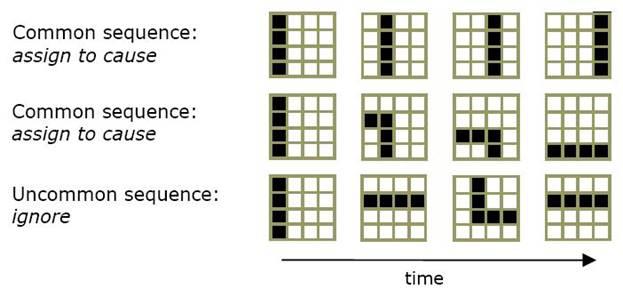
Рисунок 6b
В вышеприведенном примере не проиллюстрирована другая общая (но не всегда необходимая) функция узла. Если HTM делает предсказания, она использует свою память последовательностей для предсказания того, какие пространственные паттерны вероятнее всего появятся далее. Это предсказание в форме распределения вероятностей по изученным пространственным паттернам передается вниз по иерархии к дочерним узлам. Предсказание выступает в качестве «предпочтения», влияющего на нижестоящий узел.
Таким образом, мы можем сказать, что каждый узел в HTM сначала учится представлять наиболее часто встречающиеся пространственные паттерны во входном потоке. Затем он обучается представлять наиболее часто возникающие последовательности таких пространственных паттернов. Выход узла, идущий вверх по иерархии, является набором переменных, представляющих последовательности, или, более точно, вероятности того, что эти последовательности активны в данный момент времени. Узел также может передавать предсказываемые пространственные паттерны вниз по иерархии.
До сих пор мы рассматривали простое объяснение того, что делает узел. Сейчас мы обсудим некоторые из опций и проблем.
Обработка распределений и данных из реального мира
Паттерны на предыдущих рисунках были не реалистичными. Большинство будет иметь более 16 входных линий, и, следовательно, входные паттерны, получаемые узлом, смотрящим в реальный мир будут гораздо больше и практически никогда не будут повторяться. К тому же, элементы входных данных в общем случае имеют непрерывную градацию, не двоичную. Следовательно, узел должен иметь способность решить, какими являются обобщенные пространственные паттерны, даже если ни один из паттернов не повторялся дважды и ни один из паттернов не был «чистым».
Похожая проблема существует и в отношении временных паттернов. Узел должен определить обобщенные последовательности пространственных паттернов, но должен делать это, основываясь на распределении пространственных паттернов. Он никогда не увидит чистых данных, как показано на Рисунке 6b.
Тот факт, что узел всегда видит распределения, обозначает, что в общем случае надо не просто перечислить и сосчитать пространственные и временные паттерны. Должны быть использованы вероятностные методики. Например, идея последовательности в HTM в общем случае не такая ясная, как последовательность нот в мелодии. В мелодии вы можете точно сказать, какой длины последовательность и сколько в ней элементов (нот). Но для большинства причин в мире не ясно, когда начинается и заканчивается последовательность, и возможно отклонения в любом элементе. Аналогией могло бы быть хождение по улицам знакомого города. Выбираемый вами путь – это последовательность событий. Однако, нет набора путей по городу. «Последовательность» улиц в городе может изменяться, поскольку вы можете повернуть направо или налево на любом перекрестке. Также, не очевидны начало и конец последовательности. Но вы всегда знаете, в каком месте города вы находитесь. Пока вы передвигаетесь по улицам, вы уверены, что находитесь в том же самом городе.
Другая проблема возникает сама по себе при изучении последовательностей. Для того, чтобы сформировать последовательность, узел должен знать, когда приходит новый паттерн, то есть, где начинается элемент последовательности. Например, когда вы слышите мелодию, каждая новая нота имеет резкое начало, которое четко отмечает начало нового пространственного паттерна. Мелодия – это последовательность пространственных паттернов, где каждый паттерн отмечен началом новой ноты. Некоторые сенсорные паттерны подобны мелодиям, но большинство – нет. Если вы медленно вращаете объект, когда смотрите на него, сложно сказать, когда возникает новый пространственный паттерн. Узлы HTM должны решать, когда изменение во входном паттерне достаточно для того, чтоб отметить начало нового элемента.
Существует много прототипов того, как изучать пространственные паттерны с искаженными данными. Некоторые из этих моделей пытаются точно смоделировать часть визуального кортекса. Гораздо меньше прототипов того, как изучать последовательности распределений, по крайней мере не таким образом, как это работает в HTM.
Корпорация Numenta разработала и протестировала несколько алгоритмов для решения этих проблем. Однако, мы считаем, что алгоритмы, в особенности для изучения последовательностей, будут разрабатываться многие годы. Также есть множество вариаций алгоритмов, каждый из которых применим к конкретному сенсорному каналу или пространству задачи.
К счастью, большинству разработчиков систем, базирующихся на HTM, нет необходимости понимать детали этих алгоритмов. Они могут указывать размер узлов, размерность входных и выходных потоков и общую конфигурацию HTM, не заботясь о деталях алгоритмов обучения в узлах. Однако, мы предвидим, что некоторые люди, в особенности на начальном этапе, захотят понять эти алгоритмы и, возможно, модифицировать их. Корпорация Numenta понимает, что нам необходимо расширить алгоритмы для будущего использования и другие исследователи захотят сделать то же самое. Они могут захотеть улучшить производительность, поэкспериментировать с вариациями и модифицировать алгоритмы для подстройки их к конкретным типам задач. Чтобы облегчить это, корпорация Numenta сделает доступными исходные коды этих алгоритмов. Программная платформа Numenta разработана так, чтобы облегчить вставки в новые алгоритмы. Мы считаем, что HTM будут работать, пока алгоритмы обучения узлов будут выполнять какие-либо вариации пространственного квантования и изучения последовательностей, и, возможно, есть множество способов реализовать такие функции.
Далее мы обсудим, почему для обучения необходима изменяющаяся во времени информация.
5. Почему время так необходимо для обучения?
Ранее мы уже утверждали, что HTM могла бы выдвигать гипотезы относительно «статических» сенсорных паттернов; основным примером может являться зрение. (Вы можете распознавать изображения, когда они мелькают перед вашими глазами). Однако, мы также утверждали, что для обучения необходима изменяющаяся во времени информация. Даже системе статического зрения необходимо подавать изображения объектов, движущиеся в визуальном поле, чтоб она правильно обучалась, чтобы обнаруживала причины. Почему обучение требует изменяющейся во времени информации?
Частично мы уже дали ответ на этот вопрос. Поскольку каждый узел запоминает обобщенные последовательности паттернов, единственный способ сделать это – предоставить узлу последовательности паттернов во времени. Очевидно, что единственный путь понять язык, музыку или прикосновения – это изучение и распознавание последовательностей. Однако что насчет статического зрения? Зачем нам было бы необходимо тренировать HTM движущимися изображениями, если в конечном счете, все, что нам нужно – это распознавание статических изображений? Также, что узел будет делать со статическим паттерном, если он запомнил последовательности? Ниже мы хотим обсудить ответы на эти вопросы.
На самом базовом уровне, распознавание паттернов влечет за собой отнесение неизвестного входного паттерна к одной из нескольких категорий. Скажем, у нас есть система искусственного зрения, умеющая распознавать 1000 объектов или категорий. Существует практически неограниченное число возможных изображений, которые мы могли бы показать нашей системе и надеяться, что она отнесет каждое неизвестное изображение к правильной категории. Если «лошадь» - это одна из категорий, которые может распознать наша система, есть миллиарды визуальных паттернов, в которых вы немедленно бы распознали «лошадь». Мы хотели бы, чтобы наша система искусственного зрения делала то же самое.
Следовательно, распознавание паттернов это задача отображения «многие-к-одному». В одну категорию отображаются множество входных паттернов. Введем новый термин для описания отображения многие-к-одному: «пулинг». Пулинг обозначает назначение одного обозначения многим паттернам, то есть складывание их в один и тот же пул.
Каждый узел в HTM должен выполнять пулинг, поскольку иерархия в целом предназначена для выдвижения гипотез. Каждый узел должен делать это, даже если он просто распознает пространственные паттерны. Мы уже видели два механизма для пулинга, хотя мы и не называли таковыми. Пространственное квантование – это механизм пулинга, основанный на пространственном подобии. В этом случае мы берем неизвестный паттерн и определяем, насколько близко он к каждой из точек квантования. Два паттерна, которые в достаточной степени «перекрываются», рассматриваются как один и тот же. Таким образом, множество возможных паттернов подвергаются пулингу к точкам квантования. Это слабая форма пулинга, и сама по себе она недостаточна для решения большинства задач по выдвижению гипотез. Второй метод пулинга – это изучение последовательностей. В этом случае узел отображает множество точек квантования к единой последовательности. Этот метод пулинга более мощный, поскольку он допускает произвольное отображение. Он позволяет узлу группировать различные паттерны, которые пространственно не перекрываются. Он допускает произвольные отображения многие-к-одному.
Рассмотрим, например, распознавание изображения арбуза. Арбуз снаружи совсем не похож на внутренности арбуза. Но если бы вы увидели два изображения, одно – арбуз снаружи, а другое – внутренности арбуза, вы бы оба идентифицировали как арбуз. Нет существенного «пространственного» перекрытия между двумя этими изображениями или даже между частями изображений, так что в этом смысле это «произвольное» отображение. Откуда HTM «знает», что эти два паттерна представляют одну и ту же вещь? Кто ей сказал, что паттерн A и паттерн B, которые совершенно различны, должны рассматриваться как один и тот же? Ответ – время. Если вы держите срез арбуза в руке, двигаете его, вертите и т.п., вы видите непрерывный поток паттернов, который прогрессирует от созерцания наружной стороны арбуза к созерцанию внутренностей. Самая исходная причина, «арбуз», остается постоянной во времени по мере того, как паттерны изменяются.
Конечно, ни один узел в HTM не помнит всю последовательность целиком. Узлы внизу иерархии запоминают довольно короткие последовательности, что вызвано небольшой областью паттернов, которые он может увидеть. Узлы на следующих уровнях более стабильны. Они запоминают последовательности последовательностей от предыдущего уровня. Стабильность возрастает по мере того, как паттерны поднимаются по иерархии. При достаточном обучении вы обнаружите, что выход самого высшего узла иерархии остается стабильным в течение всей последовательности. Каждый узел в иерархии выполняет пространственный и временной пулинг. Без временного пулинга (то есть, изучения последовательностей) HTM сама по себе не смогла бы узнать, что наружная сторона и внутренности арбуза имеют общую причину.
Этот аргумент верен для большинства возможных высокоуровневых причин в мире, являются ли они по своей сути временными (такие как речь, музыка и погода), или могут быть распознаны статически (такие, как зрение). Таким образом, изменяющаяся во времени информация необходима для изучения причин мира.
Прежде чем мы продолжим обсуждение того, как HTM может распознавать статические изображения, нам необходимо отойти от темы и обсудить проблему с вышеприведенными аргументами. Есть ситуации, в которых даже при наличии временного пулинга для HTM может оказаться трудным изучить общую причину различных паттернов, по крайней мере не без некоторой помощи.
Роль учителя
Предположим, вам показали изображения еды и попросили идентифицировать каждую картинку либо как «фрукт», либо как «овощ». Если показано яблоко или апельсин, вы говорите «фрукт». Если показан картофель или лук, вы говорите «овощ». Откуда вы узнали, что и яблоко и апельсин относятся к одной и той же категории? Никогда такого не было, чтоб вы держали в руках яблоко, которое по мере поворота превращалось в апельсин. Кажется, что HTM сама по себе не могла бы изучить, используя пространственный и временной пулинг, что яблоки и апельсины должны быть сгруппированы в одну категорию.
Только что описанная задача различения «фруктов» и «овощей» ясна, но та же самая задача может возникнуть и в ситуации, подобной ситуации с арбузом. Не гарантируется, что HTM всегда будет изучать желаемые причины путем ощущения последовательностей входных паттернов. Например, что если HTM сначала была натренирована на внутренностях арбуза, а затем на его наружной стороне? Было бы естественным отнести эти отдельные паттерны к различным причинам. Следовательно, мы обучаем HTM на срезе арбуза, когда ей показывают последовательность от внутренностей до наружной стороны. Возможно, что HTM сформирует высокоуровневую причину (арбуз), которая представляет пулинг двух низкоуровневых причин (красные внутренности становятся зеленой наружной стороной). Но, также возможно, что этого не случится. Это зависит от дизайна иерархии, от того, как вы обучаете HTM и от статистики входной информации. Если переход между внутренностями и наружной стороной займет много времени, или если будет слишком много промежуточных шагов, может получиться, что HTM не совершит пулинг причин так, как вы надеетесь. Люди сталкиваются с подобной проблемой, когда изучают вещи, такие как фрукты, или кто такие художники-импрессионисты. Это не всегда очевидно из сенсорных данных.
Такой класс задач решается «в лоб». Обучение корректной категоризации, то есть обучение корректным причинам может быть выполнено гораздо быстрее и определеннее при использовании обучения с учителем. В HTM это делается путем установки предварительных ожиданий на узлах верхнего уровня иерархии в процессе обучения. Этот процесс аналогичен тому, как родители говорят «фрукты», «овощи» или «арбуз», когда ребенок играет с едой. Вы могли бы самостоятельно обнаружить, что у некоторых продуктов есть зернышки, а у других – нет, и, следовательно, обнаружит категорию, которую мы называем «фрукты», но было бы быстрее и определеннее, если бы кто-то просто сказал вам об этом.
Родители, говорящие произносящие слова, такие как «фрукт», вызывают на вершине слуховой иерархии стабильный паттерн (этот паттерн – причина, представляющая звуки слова). Этот стабильный паттерн затем влияет на визуальную иерархию, облегчая формирование желаемых категорий визуальной информации.
В HTM мы можем просто устанавливать состояния на вершине иерархии в процессе обучения. Для некоторых приложений HTM было бы лучше использовать обучение с учителем, а для других – лучше без учителя. Например, если у нас есть HTM, которая пытается обнаружить высокоуровневые причины флуктуаций на рынке ценных бумаг, мы возможно не хотели бы устанавливать в системе наши априорные гипотезы. В конце концов, цель этой системы – обнаружить причины, которые люди еще не обнаружили. В отличие от этого, если у нас есть HTM, которая используется для улучшения безопасности автомобиля путем изучения близлежащего дорожного движения, имело бы смысл использовать обучение с учителем, показывая, какие ситуации опасны, а какие – нет, не доводя до того, что система самостоятельного это обнаружит.
Распознавание статических изображений
Теперь мы можем обратиться к последнему вопросу этого раздела. Скажем, у нас есть система зрения, основанная на HTM. Мы обучаем ее с помощью изменяющихся во времени изображений. Она формирует представления причин, либо сама по себе, либо с учителем. Каждый узел в иерархии выполняет пулинг пространственных паттернов в последовательности. Теперь, когда системе представляют статическое изображение, как она сможет выдвинуть гипотезы относительно причин изображения? В особенности, зная, что HTM имеет память последовательностей паттернов, как она выдвигает гипотезы о корректных причинах, когда она видит только статическую картинку?
Ответ прост. Когда статическое изображение подается на узлы внизу иерархии, узлы формируют распределение по пространственным точкам квантования и на основе этого формируют распределение по изученным последовательностям. При отсутствии изменений во времени, распределение по последовательностям будет шире, чем в случае наличия изменений. Однако узел формирует распределение по последовательностям в любом случае. Методика Распространения Гипотез в иерархии попытается решить неоднозначность того, какая из последовательностей активна. Оказывается, что в зрительной системе часто возможно такое. То есть, в зрительной системе низкоуровневая неоднозначность, вызванная отсутствием изменений во времени, все равно может быть разрешена (путем Распространения Гипотез) по мере продвижения данных вверх по иерархии. Если изображение достаточно однозначно, на вершине иерархии будет вполне определенная причина.
Это не всегда факт. Вы можете вообразить сцену леса, в которой скрываются закамуфлированные животные. Когда вам покажут такую сцену, вы не увидите животных. Однако, если животные движутся относительно фона, даже чуть-чуть, вероятность распознавания животных резко подскакивает. В этом случае, добавочная информация о движении сжимает распределение по последовательностям на низшем уровне иерархии, чего оказывается достаточно для решения неоднозначности. Фактически, доводя эту идею до крайности, возможно представить совершенно случайное поле черных и белых пикселей, и путем движения подмножества этих случайных пикселей скоординированным образом произвести «изображение». Пространственные паттерны всегда случайны в любой момент времени, но тем не менее вы видите изображение из-за движения пикселей.
Представление времени
Для некоторых временных паттернов важно конкретное или относительное время между элементами в последовательности. Например, временные интервалы между нотами в мелодии или время между фонемами в произносимом слове – важная часть этих причин. Биологический мозг имеет возможность изучать последовательности и с конкретной временной информацией, и без. Если в последовательности есть устойчивые временные интервалы, мозг запоминает их. Если устойчивых временных интервалов нет, мозг хранит последовательность без времени. В книге Об Интеллекте было сделано предположение о том, как мозг хранит эту временную информацию. HTM нужен эквивалентный механизм для обнаружения и распознавания причин, которые требуют конкретной временной информации. К счастью, большинство приложений не требуют этого.
Мы охватили большинство концепций HTM. Следующий раздел дает ответы на наиболее часто задаваемые вопросы по технологии HTM.
6. Вопросы
Этот раздел содержит общие вопросы относительно HTM и несколько смешанных тем, которые еще не были затронуты. Нет особой необходимости знать эти материалы, чтобы развертывать системы, основанные на HTM, хотя это могло бы прояснить некоторые уже рассмотренные темы. Порядок вопросов не имеет значения.
Как мотивация и эмоции укладываются в теорию HTM?
Общий вопрос, который мы слышим, это «Кажется, мотивация и эмоции не играют никакой роли в HTM. Как HTM может знать, что важно, а что – нет?»
В биологическом мозге есть несколько систем, задействованных в эмоциональной оценке различных ситуаций. Эти эмоциональные центры являются сильно эволюционировавшими подсистемами, которые заточены для их собственных задач. Они расположены не в неокортексе. Как правило, эти эмоциональные субсистемы взаимодействуют с неокортексом довольно простым способом. Они посылают сигналы, которые распространяются по всему неокортексу. Эти сигналы относятся к скорости обучения и степени возбуждения. Это как если бы эти подсистемы говорили: «Я буду вычислять эмоциональную окраску текущей ситуации, и когда я увижу что-то важное, я скажу тебе, неокортекс, чтоб ты это запомнил».
Системы, основанные на HTM, нуждаются в аналогичном сигнале контроля обучения. Большую часть времени, он может быть настолько простым, насколько дизайнер системы решит, когда HTM должна обучаться, и с какой скоростью. HTM визуального интерфейса могла бы обучаться в лаборатории в идеальных условиях и позже развернута уже без способности к дальнейшему обучению. Некоторые приложения могли бы иметь автоматическую систему регуляции обучения, например автомобиль, который автоматически включал бы обучение, когда резко нажаты тормоза. Так что, хотя системы, основанные на HTM, не имеют эмоциональных центров как таковых, функциональная роль эмоций по отношению к неокортексу легко может быть реализована.
Что происходит с CTP? Кода и как они обучаются?
Вспомните, что Байесовские сети пересылают сообщения с гипотезами между узлами. Также вспомните, что CTP (Conditional Probability Tables, Таблицы Условных Вероятностей) являются двумерными матрицами, которые преобразуют гипотезы одного узла в пространство измерений и язык гипотез другого узла. CTP позволяют гипотезам в одном узле модифицировать гипотезы в другом узле. Ранее мы показали CTP с примером узлов, представляющих температуру и осадки. После чего мы не объяснили, как CTP обучаются.
Хотя, мы объяснили, но другим языком. В HTM CTP, используемые при прохождении информации вверх по иерархии от узла к узлу, формируются как результат изучения точек квантования. Функция квантования сама по себе является CTP. В отличие от этого, в традиционных Байесовских сетях причины в каждом узле были бы фиксированными, и CTP создавались бы путем сопоставления мгновенных гипотез между двумя узлами. Мы не можем сделать этого в HTM, поскольку причины, представленные в каждом узле, не фиксированы и должны быть изучены. Изучение точек квантования – это суть метода создания CTP на лету.
CTP, передающие сообщения вниз по иерархии между двумя узлами, могут быть обучены традиционным способом, как только будут обучены оба узла. Также в качестве нисходящей CTP возможно использование транспонированной версии восходящей CTP.
Есть еще одно отличие между реализацией CTP в HTM и в Байесовской сети. В традиционной Байесовской сети, если три дочерних узла проецируются на единый родительский узел, должно быть три отдельных CTP, каждая между своим дочерним узлом и родительским. Биология наводит на мысль, что мозг не использует такой способ. В мозге сообщения от дочерних узлов смешиваются вместе на единой функции CTP/квантования. Есть причины верить, что биологический метод лучше. Именно этот метод Numenta реализовала в своей теории HTM.
Почему количество пространственных паттернов и временных последовательностей в каждом узле фиксировано?
Есть два базовых подхода, которые могут быть использованы для изучения пространственных и временных паттернов в узле. Первый подход заключается в том, чтобы смотреть на поступающие паттерны и перечислять их. Например, при разграничении точек квантования вы могли бы постепенно строить список точек квантования по мере поступления новой информации. Если новый паттерн недостаточно близок к ранее виденным паттернам, вы создаете новую точку квантования. Если близок – вы полагаете, что этот тот же самый паттерн и не создаете новой точки квантования. С течением времени вы строите все более и более длинный список точек пространственного квантования. Тот же самый подход мог бы быть использовать для изучения последовательностей. Вы могли бы динамически строить все более и более длинный список последовательностей по мере поступления новой информации.
Второй подход заключается в том, чтобы начать с фиксированного количества точек пространственного квантования и фиксированного количества последовательностей. Изначально они имели бы случайный смысл. По мере поступления информации вы модифицируете определение существующих точек квантования и последовательностей. Например, вы брали бы новый паттерн и решали бы, к какой из изначально случайных точек квантования новый паттерн ближе всего. Затем вы модифицировали бы эти точки квантования, чтобы «сместить» их ближе к новому паттерну. Вы должны были бы делать это постепенно, поскольку другие узлы в сети зависят от выходной информации первого узла. Если бы вы слишком быстро изменяли смысл точек квантования или последовательностей, другие узлы были бы сбиты с толку.
В корпорации Numenta мы экспериментировали с обоими методами. Возможно, что оба могут работать. Сейчас мы сфокусировались на втором методе по нескольким причинам. Во-первых, мы верим, что в биологическом неокортексе используется именно этот метод. Следовательно, мы уверены, что он сможет работать на том диапазоне задач, которые может решать человек. Другая причина в том, что привязываясь к фиксированному количеству точек квантования и фиксированному количеству последовательностей в каждом узле, все обучение в системе ограничивается постепенными изменениями. Смысл причин в каждом узле изменяется медленно во времени, и, хотя другим узлам необходимо соответственно подстраиваться, ничего страшного не происходит. Размерность входной информации, выходной информации, и, следовательно, размерность CTP остаются фиксированными; изменяются только значения в матрицах.
На первый взгляд кажется проще использовать метод с переменным количеством точек квантования и последовательностей, но он может привести к трудностям, поскольку изменяются размерности входной и выходной информации.
Как представляются временные паттерны?
Общий вопрос звучит, какой длины последовательности, хранящиеся в узлах? Снова, есть два основных способа, которыми вы могли бы подойти к этой задаче; один с фиксированной длиной последовательностей, а другой – с переменной длиной. В этом случае биология использует последовательности с переменной длиной и корпорация Numenta выбрала для эмуляции этот метод, хотя это не обязательно. Чтобы дать вам понять, как это работает, мы используем музыкальную аналогию.
Вообразите, что наш узел имеет двенадцать точек квантования, каждая соответствует одной из двенадцати нот музыкальной октавы. По мере поступления информации каждая из этих двенадцати точек квантования становится активной в соответствии с тем, какая нота звучит.
Затем мы назначаем десять переменных для каждой из точек квантования. Есть десять «до», десять «ре», десять «ля бемоль» и т.д. Каждая из этих переменных представляет конкретную ноту на одном месте в одной последовательности. Узел может изучить любое количество последовательностей и последовательности могут быть любой длины, но с ограничением, что узел может работать только с десятью экземплярами каждой ноты. В одном крайнем случае узел мог бы изучить одну последовательность длиной 120 нот, если каждая нота используется точно десять раз. В другом крайнем случае он мог бы изучить шестьдесят последовательностей длиной в две ноты. Но не важно, сколько последовательностей он изучит, и не важно, какой длины каждая последовательность – ему доступны только десять экземпляров каждой ноты.
На самом деле все чуть сложнее, но эта аналогия дает основную изюминку того, как, по нашему мнению, неокортекс хранит последовательности и того, какой подход предпочитается сейчас корпорацией Numenta.
HTM построены из дискретных областей, но биологический мозг является более непрерывным. В чем разница?
До сих пор HTM описывались как иерархический набор дискретных узлов. Использование дискретных узлов присуще Байесовским сетям, и, несомненно, для любых графических вероятностных моделей.
Однако, биология наводит на мысль, что мозг работает не таким образом. В HTM нижний уровень иерархии это набор очень маленьких узлов; в мозгу нижний уровень иерархии это одна непрерывная область кортекса.
Очевидно, природный подход работает чуть лучше. Однако, у нас еще нет такого математического инструмента для понимания непрерывных моделей, какой есть для дискретных. В корпорации Numenta мы до сих пор используем подход с дискретными узлами. Мы продемонстрировали, что этот подход работает, и изучаем, можно ли его переделать, чтоб он функционировал также, как и непрерывный подход. В конечном счете мы собираемся перейти к непрерывным моделям.
HTM моделируют мир. Но делая это, они не помнят конкретных деталей и событий. Человек имеет способность помнить некоторые конкретные детали. Как это может быть реализовано в системах, основанных на HTM?
HTM, так, как они описаны в этом документе и реализованы корпорацией Numenta, не имеют способности помнить конкретные события. HTM в действительности отбрасывают детали в процессе построения модели мира. Например, если вы обучаете HTM-систему зрения распознавать собак, она не будет помнить конкретные изображения собак, на которых она обучалась. Могут быть миллионы паттернов, на которых обучалась HTM, и ни один она не будет помнить в деталях. Процесс обнаружения причин в мире – это изучение «постоянной» структуры мира, а не изучение конкретных паттернов, которые попадались только однажды.
Однако, человек помнит конкретные единичные события, особенно если событие было эмоционально окрашено. Если происходит что-то особенно плохое или особенно хорошее, вы скорее всего запомните детали этого на долгое время. Например, вы почти наверняка не помните, что вы ели на обед три недели назад. Однако, если во время еды вам стало очень плохо или с вами произошло что-то странное, вы могли бы запомнить детали этого обеда на всю оставшуюся жизнь.
В биологическом мозге гиппокамп прочно завязан на формировании этих «эпизодических» воспоминаний. Мы думаем, что достаточно понимаем отношения между гиппокампом и неокортексом, чтобы создать эквивалент «эпизодической» памяти, как дополнение к HTM. В настоящее время мы продолжаем рассматривать эту способность и в конечном счете намерены добавить ее к HTM.
Что делает фовеальная область и для чего она нужна HTM-системе?
Свет, попадающий на сетчатку на задней стороне глаза, формирует перевернутое но, с другой стороны, неискаженное изображение на сетчатке. Однако, световые рецепторы в сетчатке имеют неравномерное распределение. Имеется высокая концентрация этих клеток в центре сетчатке, называемая фовеальной областью, приводящая к искаженному представлению изображения в оптическом нерве и, в итоге, на первом уровне кортикальной иерархии. По мере движения объектов в мире или по мере движения наших глаз, возникают резкие искажения, вызванные попаданием фовеальной области в различные части визуальной сцены.
Удивительно, что для нашего визуального восприятия мира это искажение неочевидно. Теория в основе HTM объясняет, почему так происходит. Аналогично мозгу, HTM формирует высокоуровневые представления, которые инвариантны к искажению входной информации. HTM формируют высокоуровневые представления мира такого, какой он есть в действительности, а не такого, каким ощущается. Нас не заботят паттерны, приходящие от сенсоров. Нас интересуют устойчивые причины мира, и именно их обнаруживает и представляет HTM. Слепой и глухой человек формируют почти идентичные модели мира, хотя у них совершенно различные сенсорные системы. Они обнаруживают одни и те же причины через совершенно различные сенсорные паттерны. Низкоуровневые сенсорные данные – это всего лишь средство обнаружения причин в мире. Различных сенсоров или искаженной сенсорной информации достаточно до тех пор, пока они достаточно выделяют причины, которые нас интересуют при обучении.
Вопрос, который мы хотели бы рассмотреть не в том, как возникает распознавание, несмотря на наличие фовеальной области. Это всего лишь следствие того, как работает HTM. Вопрос, интересующий нас, заключается в том, значимы ли фовеальные механизмы и должны ли такие принципы применяться к HTM-системам?
Фовеальная область работает подобно механизму внимания. Что бы ни находилось в центре визуального поля – оно представляется в превосходной степени и, скорее всего, будет представлено на вершине визуальной иерархии. Движение глаз в сочетании с механизмом скрытого внимания, описанным ранее, позволяет воспринимать тонкие детали сцены. Вы можете рассматривать его в качестве механизма увеличения в видеокамере.
Теоретически, если бы плотность рецепторов по всей сетчатке была эквивалентна их плотности в фовеальной области, то было бы меньше необходимости двигать глазами. Восприятие тонких деталей могло бы быть достигнуто путем скрытого внимания. Однако, это потребовало бы гораздо больше кортекса и больше памяти. Так что, в конечном итоге фовеальная область – это средство сбережения ресурсов при сохранении остроты зрения.
Те же самые принципы были бы полезны и для некоторых приложений HTM. Например, HTM-система, изучающая погоду, могла бы иметь сенсорный массив, выбирающий данные с метеорологических станций, распределенных по территории. Эта информация могла бы быть представлена в HTM в виде двумерного массива. Однако, могла бы существовать область сенсорного массива, получающая данные со станций, расположенных ближе друг к другу. Это эквивалентно фовеальной области. Путем передислоцирования этой области высокой четкости HTM могла бы фокусироваться на метеорологических деталях в конкретной области. Множество HTM-систем могли бы использовать подобный подход.
В настоящее время, хотя в корпорации Numenta есть мысли о таких идеях, они еще не протестированы в деталях. Это интересная область для экспериментов.
Существуют ли этические вопросы относительно HTM?
Несколько лет мы обсуждали и исследовали вопрос, представляют ли HTM какую-либо этическую дилемму. Мы последовательно приходили к единогласному мнению, что HTM не представляет никакого этического отношения. Они представляют такие же выгоды и такие же потенциальные возможности неправильного использования, как и многие другие технологии, такие как компьютеры или Интернет. Эти темы более детально обсуждаются в книге On Intelligence.
7. Выводы
HTM охватывают алгоритмические и структурные свойства неокортекса, и, как таковые, представляют первую возможность решить множество ранее неразрешимых задач распознавания паттернов и машинного интеллекта. Проще рассматривать HTM как то, что применимо для задач, которые кажутся простыми людям, но трудны для компьютеров. Однако, алгоритмические свойства HTM очень гибкие, и, следовательно, как только они будут поняты, они могут быть применены к множеству проблем за пределами человеческих способностей.
Возможности
Самая передовая возможность технологии HTM – это ее способность обнаруживать причины, лежащие в основе сенсорных данных. Причины – это устойчивые и повторяющиеся структуры в мире. Концепция «причин» охватывает все от языка до физических объектов, идей, законов физики, действий других людей. Подобно человеку, HTM могут обучаться моделировать все эти вещи и даже более. При подключении к HTM одного или более сенсоров, HTM постепенно и автоматически строит внутреннее представление причин в ее мире. Эта фаза обучения требует повторяющейся экспозиции сенсорной информации во времени. Причины должны оставаться неизменными во время обучения.
Есть целая иерархия причин, сосуществующих в мире в один момент времени, и HTM строит соответствующую иерархию представлений. Мгновенное значение этих представлений называется гипотезами.
Представления, сформированные на вершине иерархии – это высокоуровневые причины. Эти высокоуровневые причины остаются неизменными в течение очень долгого периода времени, и могут охватывать все сенсорное пространство. Причины, представленные на нижних уровнях иерархии охватывают более короткие периоды времени и более мелкие области сенсорного пространства.
Обнаружение причин является необходимым первым шагом к дальнейшему распознаванию, но для многих приложений он является и последним.
После обнаружения причин, HTM может легко выдвинуть гипотезу о причинах, лежащих в основе нестандартной информации. Выдвижение гипотез подобно «распознаванию паттернов». Когда HTM видит нестандартную информацию, она определяет не только наиболее правдоподобную высокоуровневую причину(ны) этой информации, но также и иерархию подпричин. Дизайнеры HTM-систем могут делать запрос к HTM, чтобы увидеть, что было распознано.
Каждый узел в сети может использовать свою память последовательностей для предсказания того, что должно произойти дальше. Серия предсказаний – это базис для воображения и целенаправленного поведения.
HTM могут реализовывать несколько типов внимания. Скрытое внимание может быть достигнуто путем выборочного запрещения путей в иерархии; это позволит HTM уделять внимание подмножеству всей ее входной информации. Установка предпочтений внимания может быть достигнуто путем установки желаемых гипотез на вершине иерархии; это даст направленный поиск. Явное внимание включает манипулирование объектами через поведение.
Технология
Технически HTM могут рассматриваться как форма Байесовских сетей, где сеть состоит из набора узлов, упорядоченных в древовидной иерархии. Каждый узел в иерархии самостоятельно открывает набор причин в его входной информации через процесс поиска обобщенных пространственных паттернов и затем через процесс поиска обобщенных временных паттернов. В отличие от множества Байесовских сетей, HTM являются самообучаемыми, имеют четко определенные отношения отцы/дети между узлами, по своей сути манипулируют изменяющимися во времени данными и предоставляют механизм скрытого внимания.
Сенсорные данные подставляются в самый низ иерархии. Для обучения HTM необходимо предоставить непрерывный, изменяющийся во времени поток данных, причем причина, лежащая в основе этого потока данных, должна быть устойчивой в окружении. То есть, вы либо двигаете сенсоры HTM в мире, либо объекты в мире двигаются относительно сенсоров HTM.
Выдвижение гипотез также выполняется над изменяющейся во времени информацией, хотя, в некоторых случаях, таких как зрение, возможно выдвижение гипотез над статической информацией.
В процессе выдвижения гипотез информация течет вверх по иерархии, начиная с узлов самого нижнего уровня, наиболее близких к сенсорам. По мере продвижения информации вверх по иерархии, последовательно в узлах более высокого уровня формируются гипотезы, каждая представляющая причины во все больших и больших пространственных областях и на все больших и больших периодах времени.
Методика, подобная Распространению Гипотез, ведет к тому, что все узлы сети быстро приходят к гипотезам, согласующимся с сенсорными данными. Предсказание сверху вниз может влиять на процесс выдвижения гипотез, путем склонения сети к выбору из предсказанных причин.
HTM являются системами памяти. Под этим мы подразумеваем, что HTM должны изучать их мир. Иногда вы можете выступать в роли учителя в процессе обучения, но вы не можете запрограммировать HTM. Все, что HTM изучает, хранится в матрице памяти в каждом узле. Эти матрицы памяти представляют точки пространственного квантования и последовательности, запомненные узлами.
Поскольку это новая технология, есть множество вещей, которые нам предстоит понять относительно HTM. Например, нам необходимо улучшить наши способности к измерению и определению емкости HTM. Нам необходимо разработать полезные эвристики, чтобы знать, какая иерархия будет лучше соответствовать конкретной задаче. Нам необходимо многое сделать, чтобы улучшить методы обучения. И хотя мы разработали алгоритмы для пространственного квантования и времязависимого пулинга, мы уверены, что они могут быть и будут улучшены. Пройдут годы продвижений и улучшений, пока мы научимся использовать эту технологию.
Первая реализация платформы Numenta HTM сделана для компьютеров с системой Linux. Платформа работает на всем, начиная с одного процессора и заканчивая множеством процессоров. Мы предвидим, что специально для HTM в конце концов будут разработаны различные виды пользовательского оборудования, но сегодня это необязательно.
Результаты
HTM – это новая мощная вычислительная парадигма, которая может быть в конечном счете приравнена по важности к традиционным программируемым компьютерам в смысле общественного влияния и финансовых возможностей.
Одна из целей корпорации Numenta – максимизировать преимущества технологии HTM. Подход, предпринятый нами для этого – создать платформу, которая поможет инженерам и ученым экспериментировать с технологией HTM, разрабатывать HTM-приложения и создавать впечатляющие возможности в бизнесе, основанные на HTM. В дополнение к документированию платформы и инструментов, Numenta сделает доступным исходные коды для многих частей платформы. Доступ к исходному коду должен позволить разработчикам понять, как работают инструменты корпорации Numenta, и обеспечить возможность и финансовые стимулы для расширения платформы.
Поскольку HTM моделирует широкомасштабные структуру и функцию неокортекса, инструменты Numenta также должны быть полезны в области психологии, образования, психиатрии и нейронауке как способ для исследования способностей здоровых людей и для улучшения понимания психических расстройств.
Мы только начали разрабатывать эту новую необозримую парадигму интеллектуальных вычислений, основанную на технологии HTM. Сегодня мы совмещаем платформу и теоретические исследования. В грядущие годы мы собираемся сделать большой прогресс в понимании ограничений HTM, того, как они будут масштабироваться, как они будут функционировать и какие проблемы будут решать.
Что наиболее важно, мы смотрим вперед, чтобы организовать сообщество людей, работающих над этой технологией и применяющих ее к широкому диапазону задач из реального мира.
© 2006 Numenta, Inc.