Рассмотрим временную диаграмму работы памяти с синхронным интерфейсом.
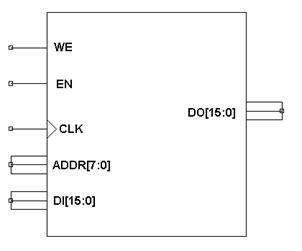
Рис. 5.14 Графическое изображение блока синхронной памяти
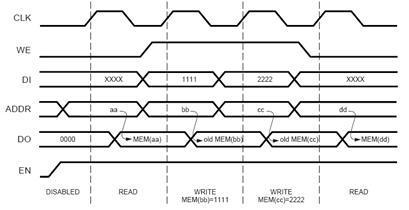
Рис. 5.15 Временные диаграммы работы синхронной памяти
Представленная на рис. 5.14 память (библиотечный элемент САПР ISE) имеет следующие сигналы:
1) CLK – тактовый сигнал, по фронту которого происходят все изменения состояния памяти.
2) DI (DataInput) – вход данных для записи.
3) ADDR – вход адреса.
4) WE (WriteEnable) – сигнал разрешения записи. Если в момент фронта сигнала CLK на WE присутствует активный уровень (в данном случае – логическая «1»), происходит запись данных, присутствующих в этот момент на входе DI, в ячейку памяти с адресом, присутствующим на ADDR.
5) EN – вход разрешения работы. Неактивный уровень сигнала на этом входе запрещает изменение выходов блока памяти или запись новых данных.
6) DO (DataOutput) – выход данных.
Как видно из временной диаграммы, представленной на рис. 5.15, данные на выходе (линии DO) появляются с некоторой задержкой относительно фронта тактового сигнала. При чтении (WE неактивный) на выходах появляется содержимое ячейки, адрес которой присутствовал на адресных линиях непосредственно перед приходом фронта тактового сигнала. При записи на выходы передается предыдущее значение ячейки, в которую происходила запись. Особенностью блочной памяти ПЛИС является возможность настройки того, какое именно значение будет появляться на выходах при записи. На приведенной выше диаграмме показана работа в режиме «чтение перед записью» (ReadbeforeWrite). Альтернативными режимами являются «чтение после записи» (ReadafterWrite), при котором на выходах будет скопировано входное значение, и «нет чтения при записи» (noReadonWrite), при котором состояние выходов не изменится.
В случае хранения кода порядок обновления выхода данных вряд ли имеет большое значение, поскольку крайне маловероятна ситуация, когда программное обеспечение производит запись в память кода и на следующем же такте исполняет этот код. Большинство проектов для небольших процессоров обычно используют режим кросс-компиляции, когда код создается на более мощной ЭВМ и загружается в память ПЛИС либо с помощью одного из стандартных интерфейсов, либо в виде предустановленных значений в ячейках блочной памяти (в этом случае ячейки инициализируются в процессе загрузки конфигурации ПЛИС). В любом случае, основным режимом работы, который и требуется в данном случае от синхронной памяти, является режим непрерывной подачи на вход управляющего блока последовательности команд для их исполнения.
В отличие от памяти с асинхронным интерфейсом, синхронная память не позволит реализовать режим работы, при котором перед каждым новым фронтом тактового сигнала на входе cmd присутствовал бы код новой команды. Эту проблему иллюстрирует временная диаграмма, представленная на рис. 5.16.
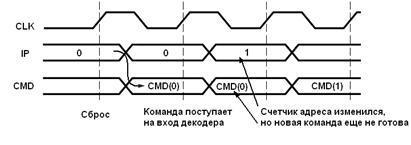
Рис. 5.16 Временные диаграммы работы устройства, состоящего из управляющего автомата и синхронной памяти
Как видно из представленной диаграммы, смена адреса ip сама по себе не приводит к появлению нового кода на выходе синхронной памяти. Чтобы состояние выхода было обновлено, необходимо подать на вход этой памяти фронт тактового сигнала. Однако этот фронт не может быть использован управляющим автоматом, поскольку на его входе cmd все еще присутствует старое значение. Таким образом, для поддержания непрерывного цикла «считывание-исполнение» требуется как минимум два такта, один из которых используется синхронной памятью для обновления кода команды на своем выходе, а второй – управляющим устройством для собственно исполнения команды, включая сюда формирование нового адреса ip для продолжения работы процессора.
Процессор с двухтактным циклом работы является наиболее простым вариантом полностью синхронного устройства на базе ПЛИС. Данный пример вполне может быть использован в практике проектирования, поэтому рассмотрим порядок проектирования процессорного устройства такого типа более подробно.
Для учебного примера необходимо определить архитектуру процессора и уточнить систему команд. С целью демонстрации возможности выполнения основных операций целесообразно ограничиться двумя регистрами общего назначения. Назовем их A и B. Далее, процессор обязательно должен иметь указатель инструкций IP. Наконец, для демонстрации вызова подпрограмм с последующим возвратом требуется регистр, хранящий адрес, с которого произошел вызов подпрограммы (в простом примере можно ограничить возможности процессора всего одним уровнем вложенности вызовов). Назовем этот регистр R. Ограничимся также для всех регистров 8 разрядами.
Минимальным набором команд, достаточным для демонстрации основных возможностей процессора, являются:
– команда пересылки «регистр-регистр»;
– команды непосредственной загрузки (в регистр загружается литерал – численная константа);
– команда безусловного перехода к новому адресу;
– команды перехода по условию;
– команда вызова подпрограммы;
– команда возврата из подпрограммы;
– набор арифметико-логических операций между регистрами общего назначения.
Чтобы упростить процедуру декодирования и обеспечить выполнение всех команд процессора за один цикл, используем в системе команд слабое кодирование – отдельные поля командного слова будут содержать литералы, требуемые командам непосредственной загрузки, переходов и вызова подпрограмм. Для этого необходимо, чтобы разрядность команды была больше, чем разрядность литералов, передаваемых в регистры. Можно использовать 16-разрядный код команды, хотя это и избыточно. Тогда систему команд проектируемого процессора можно представить в следующем виде
Код операции |
Мнемоника |
Описание |
0 |
NOP |
Нет операции |
01xxH |
JMP |
Безусловный переход по адресу, заданному младшим байтом команды |
02xxH |
JMPZ |
Переход по адресу, заданному младшим байтом команды, если содержимое регистра A равно нулю. |
03xxH |
CALL |
Вызов подпрограммы по адресу, заданному младшим байтом команды. |
04xxH |
MOV A, xx |
Непосредственная загрузка в регистр A значения, заданного младшим байтом команды |
05xxH |
MOV B, xx |
Непосредственная загрузка в регистр B значения, заданного младшим байтом команды |
0600H |
RET |
Возврат из подпрограммы. |
0601H |
MOV A, B |
Загрузка в регистр A значения, содержащегося в регистре B |
0602H |
MOV B, A |
Загрузка в регистр B значения, содержащегося в регистре A |
0603H |
XCHG A, B |
Обмен местами значений в регистрах A и B |
0604H |
ADD A, B |
Сложение значений в регистрах A и B, результат помещается в A |
0605H |
SUB A, B |
Вычитание значений в регистрах A и B, результат помещается в A |
0606H |
AND A, B |
Побитное логическое И значений в регистрах A и B, результат помещается в A |
0607H |
OR A, B |
Побитное логическое ИЛИ значений в регистрах A и B, результат помещается в A |
0608H |
XOR A, B |
Побитное логическое ИСКЛЮЧАЩЕЕ ИЛИ значений в регистрах A и B, результат помещается в A |
Данная система команд позволит продемонстрировать работоспособность созданного процессора. Для этого можно будет создать программу, загружающую в регистры общего назначения произвольные числа, выполняющие одну из арифметико-логических операций над ними и входящую в бесконечный цикл путем перехода к выполнению замкнутого цикла JMP. Следует заметить, что отсутствие программных тестов работоспособности создаваемых процессорных устройств часто является серьезным препятствием к их планомерному и эффективному проектированию. Необходимо обращать внимание прежде всего на команды непосредственной загрузки и безусловных переходов, которые позволят наглядно продемонстрировать работоспособность создаваемой конструкции и убедиться, что временные характеристики использованной элементной базы удовлетворяют техническим требованиям. Впоследствии система команд может быть наращена до требуемого уровня. В то же время, ориентируясь на разнообразие систем команд современных микропроцессоров, разработчики могут пойти по пути наращивания функциональности арифметико-логического устройства, заложив в архитектуру изначально неработоспособные решения. В данном случае рекомендуется придерживаться принципа «работоспособный проект с неполной функциональностью предпочтительнее набора полностью завершенных модулей, которые не составляют готового процессора».
Рассмотрим последовательность создания процессора с системой команд, приведенной выше. Как и в предыдущем варианте, разделим конструкцию на ядро (управляющий автомат) и память программ. Модуль, реализующий ядро, должен содержать:
– тактовый вход clk;
– вход команды cmd;
– выход счетчика адреса ip.
Кроме того, необходимо иметь возможность просмотреть состояние регистров процессора или использовать их для организации интерфейса с внешними устройствами. Поэтому в список интерфейсных сигналов модуля необходимо включить также сигнала a и b.
Поскольку в процессе работы производится как чтение регистров, так и запись в них (т.е. регистры находятся как по левую, так и по правую стороны оператора присваивания), необходимо объявить их как двунаправленные сигналы, с ключевым словом inout. То же относится и к счетчику адреса ip, поскольку для его увеличения необходимо будет использовать оператор ip<= ip + 1; , что, очевидно, также потребует как чтения, так и записи.
Шаблон модуля управляющего автомата с указанными сигналами можно создать как непосредственным вводом текстового описания, так и с использованием мастера создания нового компонента (например, в САПР ISE). После правильного ввода имен сигналов, их разрядностей и направлений передачи должен получиться следующий исходный текст.
library IEEE;
use IEEE.STD_LOGIC_1164.ALL;
use IEEE.STD_LOGIC_ARITH.ALL;
use IEEE.STD_LOGIC_UNSIGNED.ALL;
entityproc_two_stage is
Port ( clk : in std_logic;
cmd : in std_logic_vector(15 downto 0);
ip :inoutstd_logic_vector(7 downto 0);
a :inoutstd_logic_vector(7 downto 0);
b :inoutstd_logic_vector(7 downto 0));
endproc_two_stage;
architecture Behavioral of proc_two_stage is
begin
endBehavioral;
Листинг. Объявление сигналов в модуле управляющего автомата процессора с синхронной архитектурой.
Далее следует определить список вспомогательных переменных, которые потребуются для нормального функционирования данного модуля. Исходя из планируемой архитектуры, цикл работы процессора должен состоять из двух тактов: выборки команды и ее исполнения. Номер текущего такта, очевидно, должен храниться во внутренней переменной и использоваться для определения действий, выполняемых по очередному фронту тактового сигнала. Поскольку состояний всего два, для их однозначного описания достаточно однобитной переменной, которая может иметь тип std_logic. При большем количестве тактов процессора на один цикл работы потребуется большее количество разрядов, и тип переменной следует устанавливать как std_logic_vector. Кроме того, во всех случаях можно объявить тип integer, указав границы изменения значений. В данном случае нет существенной разницы, какой именно тип использовать, поскольку синтезированные схемы окажутся эквивалентными.
Далее, в системе команд присутствуют команды вызова подпрограмм и возврата из подпрограммы. Данные действия реализуются с использованием стека, хранящего адрес программы, из которого произошел вызов. При возврате происходит запись в счетчик команд значения со стека, ранее запомненного на нем в процессе вызова подпрограммы. Для реализации этого механизма требуется наличие стека, или хотя бы одной его ячейки, способной запоминать адрес вызова и впоследствии загружать его в счетчик команд при возврате из подпрограммы. Ограничимся на данном этапе одной ячейкой стека (что позволит реализовать ее просто в виде регистра).
С учетом сказанного, для управляющего автомата потребуется однобитная переменная, хранящая номер такта в цикле работы (например, с именем stage), и 8-разрядный регистр r, хранящий адрес вызывающей команды. Для этого после строки, начинающейся с ключевого слова architecture, необходимо вставить следующие объявления:
signal stage : std_logic;
signal r : std_logic_vector(7 downto 0);
Наконец, приступим к описанию собственно автомата. Синхронная работа по фронту тактового сигнала подразумевает, что описание будет основано на операторе process, как показано в следующем фрагменте.
process(clk)
begin
ifclk'event and clk = '1' then
-- операторы
end if;
end process;
Поскольку цикл работы включает в себя два такта, в первую очередь необходимо сделать выбор, основываясь на текущем номере такта в данном цикле. Этот выбор делается с помощью конструкции case (с точки зрения VHDL и синтезируемых аппаратных структур она обычно предпочтительнее, чем цепочка операторовif).
case stage is
when '0' => stage <= '1';
whenothers =>stage<= '0';
-- операторы, декодирующие код команды
endcase;
В первом такте каждого цикла (stage=’0’) выполняется простое присваивание stage<= '1'. Это связано с тем, что в данном такте работает синхронная память кода, а управляющий автомат ожидает поступления очередной команды на вход cmd, и не выполняет никаких действий (за исключением, разумеется, изменения значения stage).
Во втором такте каждого цикла происходит собственно исполнение команды путем изменения значений регистров (согласно описанию команд). При этом на входе cmd уже присутствует очередная команда. Поэтому достаточно декодировать cmd, также с помощью единственного оператора case.
В приведенном фрагменте вместо условия when ‘1’ было использовано условие whenothers. Это связано с тем, что в текущих реализациях трансляторов VHDL вариант others обязателен к перечислению, даже если предыдущие варианты описали все возможные состояния переменной-селектора. В данном случае условие others включает в себя как раз состояние переменной stage, равное 1.
Оператор, исполняющий команды путем декодирования переменной-селектора cmd, выглядит следующим образом.
caseconv_integer(cmd) is
when<код1> => ...
when<код2> => ...
endcase;
Для того, чтобы в отдельных ветках оператора можно было использовать десятичные значения отдельных кодов (а не их поразрядные двоичные представления), в качестве переменной-селектора используется выражение conv_integer(cmd). Для реализации собственно исполнения команд необходимо описать действия, выполняемые при каждом допустимом значении кода команды. Эти действия состоят в назначении регистрам новых значений в соответствии с описанием команд. При этом необходимо помнить, что счетчик команд является равноправным регистром, и не обновляется автоматически (к чему можно привыкнуть, работая с языками программирования ЭВМ). Поэтому в каждом варианте кода команды присваивание счетчику нового значения должно быть указано явно. Например, команда NOP (нет операции) реализуется следующей строкой.
when 0 =>ip<= ip + 1;
Т.е., несмотря на то, что согласно описанию, никакие действия команда не выполняет, происходит увеличение счетчика команд. Обычно в описаниях команд различных процессоров делается оговорка, что команда NOP не влияет на процессор «за исключением счетчика команд». Отсутствие такого оператора приведет к попаданию управляющего автомата в бесконечный цикл считывания команды NOP из одной и той же ячейки памяти и ее исполнению, не приводящему к переходу к следующей ячейке. Поэтому отслеживание операций со счетчиком команд в каждом из вариантов оператора case является крайне важным. Естественно, для выполнения безусловных переходов, вызовов подпрограмм и т.п. вместо увеличения счетчика команд на единицу выполняется непосредственная загрузка в него нового значения.
На примере команды безусловного перехода удобно проиллюстрировать еще один вопрос процесса описания команд. Как упоминалось выше, в отдельных ветках оператора case необходимо перечислить все команды, которые должны исполняться процессором. Значит ли это, например, что для команды безусловного перехода необходимо перечислить 256 вариантов, соответствующих 256 адресам, на которые возможен переход? Очевидно, что общий объем исходного текста и трудоемкость его создания существенно возрастают.
В действительности таких непроизводительных действий легко можно избежать. Обратившись к системе команд, можно убедиться, что команда безусловного перехода имеет формат 01xxH, где xx – адрес, на который происходит переход. Иными словами, если старшие 8 разрядов команды содержат код 01, то 8 младших разрядов содержат адрес перехода (здесь наглядно проявляется элемент слабого кодирования – в старших разрядах содержится тип команды, а в младших – ее аргумент). Поэтому все коды от 256 до 511 могут быть обработаны по одной и той же схеме:
when 256 to 511 =>ip<= cmd(7 downto 0);
Здесь из сигнала cmd выделяются 8 младших разрядов и записываются в счетчик команд. Аналогично, хотя и с некоторыми замечаниями, организуются условные переходы.
when 512 to 767 =>ifconv_integer(a) = 0
thenip<= cmd(7 downto 0);
elseip<= ip + 1;
endif;
В данном фрагменте видно, что при обработке условных переходов (коды 2xxH, или 512–76710) возможны два варианта. Если условие перехода выполняется (в данном случае регистр a должен быть равен нулю), в счетчик команд загружаются 8 младших разрядов cmd. Однако если условие не выполняется, процессор должен продолжить выполнять программу со следующего адреса. Поэтому часть else условного оператора должна быть явно определена и содержать оператор ip<= ip + 1.
С условными переходами и их организацией в конфигурируемых процессорах связано достаточно много интересных замечаний. Как можно увидеть в приведенном выше примере, условный переход организован непосредственно на базе анализа значения регистра a, в то время как привычным способом организации условных переходов является переход по значению некоторого флага (например, флага нуля, переноса и т.д.). Действительно, в рассматриваемом процессоре такой подход также возможен: можно ввести флаг нуля, определить влияние на него различных команд, и, имея в составе процессора переменную zf (от ZeroFlag), производить условные переходы на основе ее анализа. В то же время использование непосредственно значений регистров не противоречит каким-то положениям цифровойсхемотехники.
Следует заметить, что использование флагов в качестве переменных, определяющих условия перехода, позволяет организовывать в имеющихся процессорах объединение нескольких регистров в значение с большей разрядностью. В этом случае, например, сравнение регистра a с нулем установит или сбросит флаг нуля, а последующее сравнение a и b оставит флаг нуля установленным, только если оба регистра были равны нулю. Таким образом можно выполнить проверку на ноль числа, отдельные фрагменты которого размещены в нескольких регистрах. Для конфигурируемых процессоров можно использовать как стандартный подход, так и команды переходов на основе прямого сравнения регистров с константами. Важно, что в систему команд можно вводить те условия
Рассмотрим реализацию команды вызова подпрограмм. Само действие служит для временной передачи управления на некоторый адрес с последующим возвратом к основной программе. Поэтому процессор должен иметь возможность запоминания адреса, по которому следует продолжать выполнение основной программы. Признаком продолжения основной программы является выполнение команды возврата из подпрограммы (обычно имеющей мнемонику RET).
Следовательно, при исполнении команды вызова (CALL) процессор должен занести в регистр r текущее значение счетчика команд и одновременно загрузить в него новый адрес, на который происходит переход. В момент возврата из подпрограммы (выполнения команды RET) значение, сохраненное в регистре r, загружается в счетчик команд, предварительно увеличиваясь на единицу. Это увеличение необходимо для того, чтобы возврат произошел не к тому же адресу (по которому размешена команда CALL), а к следующему адресу в последовательности команд. Очевидно, данный порядок вызова может быть и изменен: в регистр r записывается значение, увеличенное на единицу, а при возврате увеличение не производится.
В общем случае сохранение адреса вызова происходит не в одиночном регистре, а на стеке, поскольку одиночный регистр исключает возможность вложенных вызовов подпрограмм.
Последовательность выполнения инструкций при вызове подпрограмм проиллюстрирована на рис. 5.17.
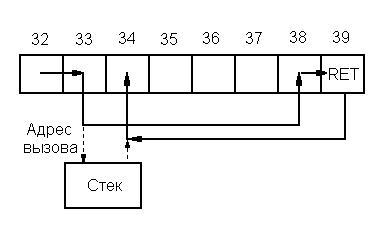
Рис. 5.17 Последовательность выполнения инструкций при вызове подпрограмм
Исполнение команды вызова подпрограмм реализуется следующей строкой на VHDL:
when 768 to 1023 => r <= ip; ip<= cmd(7 downto 0);
Возврат из подпрограммы:
when 1536 =>ip<= r + 1;
В данном случае использован подход, когда запоминается адрес той процедуры, которая непосредственно вызывала подпрограмму, а увеличение адреса на единицу выполняется при возврате из подпрограммы. Этот подход приемлем для данной архитектуры, однако может быть использован только в том случае, когда длина команды вызова подпрограммы строго постоянна (в данном случае это одно 16-разрядное слово), поэтому следующая команда обязательно расположена по адресу, увеличенному на единицу. В отличие от этого для архитектуры x86 подобный подход неприменим, поскольку команда вызова подпрограммы может иметь разную длину в байтах. Длина этой команды известна в момент ее исполнения, поэтому имеется возможность отправить на стек точный адрес следующей команды. Следовательно, при переменной длине команды вызова подпрограммы единственным вариантом является запоминание на стеке (или в регистре) того адреса, с которого следует продолжать выполнение программы. В этом случае реализация команд вызова и возврата должна быть следующей:
when 768 to 1023 => r <= ip + 1;
ip<= cmd(7 downto 0);
when 1536 =>ip<= r;
Арифметико-логические команды всех типов реализуются схожим образом:
when<код> =><reg><= <выражение>; ip<= ip + 1;
Например:
when 1540 => a <= a + b; ip<= ip + 1;
Указанному шаблону соответствуют, с небольшими вариациями, большинство арифметико-логических команд. Поэтому успешная реализация одной из них, как правило, свидетельствует о принципиальной работоспособности остальных команд подобного типа (не рассматривая ситуации, когда использовано некорректное описание).
Полный исходный текст модуля управляющего автомата приведен ниже:
library IEEE;
use IEEE.STD_LOGIC_1164.ALL;
use IEEE.STD_LOGIC_ARITH.ALL;
use IEEE.STD_LOGIC_UNSIGNED.ALL;
entityproc_two_stage is
Port ( clk : in std_logic;
cmd : in std_logic_vector(15 downto 0);
ip :inoutstd_logic_vector(7 downto 0);
a :inoutstd_logic_vector(7 downto 0);
b :inoutstd_logic_vector(7 downto 0));
endproc_two_stage;
architecture Behavioral of proc_two_stage is
signal stage : std_logic;
signal r : std_logic_vector(7 downto 0);
begin
process(clk)
begin
ifclk'event and clk = '1' then
case stage is
when '0' => stage <= '1';
when others =>
stage<= '0';
caseconv_integer(cmd) is
when 0 =>ip<= ip + 1;
when 256 to 511 =>ip<= cmd(7 downto 0);
when 512 to 767 => if conv_integer(a) = 0
thenip<= cmd(7 downto 0);
elseip<= ip + 1;
end if;
when 768 to 1023 => r <= ip;
ip<= cmd(7 downto 0);
when 1024 to 1279 => a <= cmd(7 downto 0);
ip<= ip + 1;
when 1280 to 1535 => b <= cmd(7 downto 0);
ip<= ip + 1;
when 1536 =>ip<= r + 1;
when 1537 => a <= b; ip<= ip + 1;
when 1538 => b <= a; ip<= ip + 1;
when 1539 => a <= b; b <= a; ip<= ip + 1;
when 1540 => a <= a + b; ip<= ip + 1;
when 1541 => a <= a - b; ip<= ip + 1;
when 1542 => a <= a and b; ip<= ip + 1;
when 1543 => a <= a or b; ip<= ip + 1;
when 1544 => a <= a xor b; ip<= ip + 1;
when others =>ip<= ip + 1;
end case; -- cmd
end case; -- stage
end if;
endprocess;
endBehavioral;
После трансляции полученного модуля необходимо создать блок синхронной памяти с организацией 256х16 (поскольку 8-разрядный сигнал ip адресует 256 ячеек памяти, а входная шина cmd имеет разрядность 16). Такой блок может быть создан различными способами, в том числе с помощью встроенных шаблонов САПР и разнообразных программ-генераторов. Процессор, содержащий синхронный управляющий автомат и синхронную память, представлен на рис. 5.18.
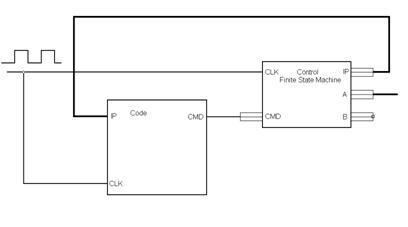
Рис. 5.18 Процессорна базе синхронного управляющего автомата
и синхронной памяти команд
Полученный проект не использует специфичных ресурсов какой-либо серии ПЛИС и может быть реализован как на базе программируемой логики, так и в заказной микросхеме(ASIC, Application-SpecificIntegratedCircuit). Синхронная архитектура и исполнение всех операций только по фронту тактового сигнала позволяет данному проекту широко использовать возможности современной элементной базы по реализации синхронных устройств. Поэтому оценки тактовой частоты, производимые САПР ПЛИС, достаточно высоки для программируемой логики. Следует отметить, что в приведенном примере отсутствуют внекристальные соединения, а все сигналы, в том числе и команды, выбираемые из памяти, передаются непосредственно по кристаллу ПЛИС. Поэтому задержки их распространения достаточно малы, а оценка средствами САПР обладает большой степенью надежности.