Искусственный интеллект
-
2021-06-04 18:49:49
Ученые представили концепцию модели на основе ИИ, которая умеет мыслить как человек. Исследователи уже представили ее первую сборку.
eiot : -
2021-04-29 08:39:54
Пересказ интервью новатора в сфере ИИ Джеффа Хокинса, переносящего принципы работы человеческого мозга на компьютеры.
 eiot :
eiot : -
2020-12-01 07:59:27
Ученые из лаборатории Командования по развитию боевого потенциала армии США (DEVCOM) разработали алгоритм машинного обучения для моделирования и декодирования мозговых волн. Технология самостоятельно разделяет динамические паттерны в сигналах мозга и расшифровывает поведение или состояние человека. Авторы предлагают использовать алгоритм сразу в нескольких системах — в переговорах без слов, в лечении неврологических расстройств и для анализа физического состояния на любом расстоянии.
 eiot :
eiot : -
2018-05-10 15:42:57
Most animals, including humans, are able to flexibly navigate the world they live in – exploring new areas, returning quickly to remembered places, and taking shortcuts. Indeed, these abilities feel so easy and natural that it is not immediately obvious how complex the underlying processes really are. In contrast, spatial navigation remains a substantial challenge for artificial agents whose abilities are far outstripped by those of mammals.
 eiot :
eiot : -
2018-03-22 13:32:11
Разработчики из Google Brain доказали, что «противоречивые» изображения могут провести как человека, так и компьютер; и возможные последствия — пугающие.
 eiot :
eiot : -
2017-10-04 08:13:13
A new prior is proposed for representation learning, which can be combined with other priors in order to help disentangling abstract factors from each other. It is inspired by the phenomenon of consciousness seen as the formation of a low-dimensional combination of a few concepts constituting a conscious thought, i.e., consciousness as awareness at a particular time instant. This provides a powerful constraint on the representation in that such low-dimensional thought vectors can correspond to statements about reality which are true, highly probable, or very useful for taking decisions. The fact that a few elements of the current state can be combined into such a predictive or useful statement is a strong constraint and deviates considerably from the maximum likelihood approaches to modelling data and how states unfold in the future based on an agent's actions. Instead of making predictions in the sensory (e.g. pixel) space, the consciousness prior allows the agent to make predictions in the abstract space, with only a few dimensions of that space being involved in each of these predictions. The consciousness prior also makes it natural to map conscious states to natural language utterances or to express classical AI knowledge in the form of facts and rules, although the conscious states may be richer than what can be expressed easily in the form of a sentence, a fact or a rule.
 eiot :
eiot : -
2017-03-06 09:32:09
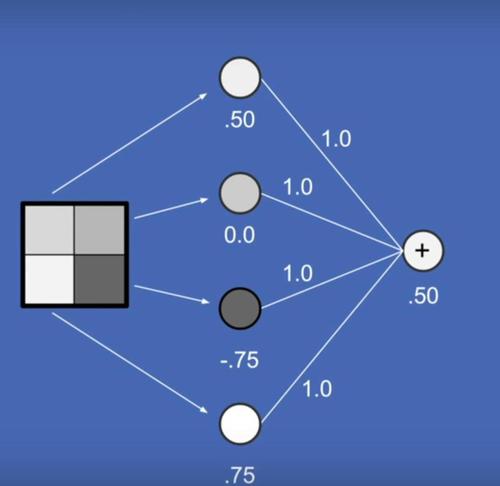
A gentle introduction to the principles behind neural networks, including backpropagation. Rated G for general audiences.
 eiot :
eiot : -
2016-10-24 12:15:14
Режисер: Рои Коен (Roy Cohen)
Производство: Roast Beef Productions & France TV (США... eiot :
eiot : -
2016-09-24 14:44:25
Этот документ детально описывает новые алгоритмы обучения и предсказания состояний, разработанные в компании Numenta в 2010 году.
 eiot :
eiot : -
2016-09-24 14:22:23
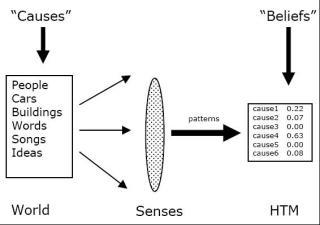
"Динамическая Иерархическая Память" (англ. Hierarchical Temporal Memory или HTM) - новая технология искуственного интеллекта, прототипом которой послужили организация и алгоритмы работы коры головного мозга млекопитающих.
 eiot :
eiot : -
2016-09-24 14:22:23
Концепции, Теория и Терминология
Джеф Хокинс и Дайлип Джордж, Numenta Inc.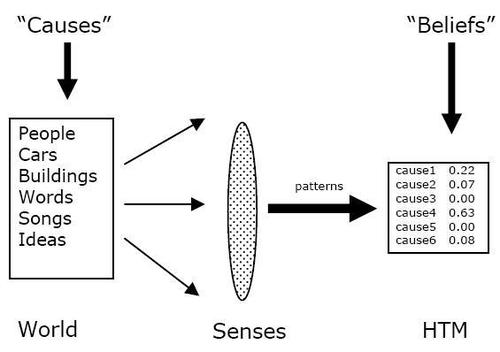 eiot :
eiot : -
2016-09-24 14:22:23
Сейчас все кому не лень говорят о модных технологиях глубокого обучения, как будто это манна небесная. Но понимают ли говорящие, что это на самом деле? А ведь у этого понятия нет формального определения, и объединяет оно целый стек технологий. В этом посте я и хочу популярно, насколько это возможно, и по сути объяснить что стоит за этим термином, почему он так популярен и что дают нам эти технологий.
 eiot :
eiot : -
2016-09-24 14:00:33
NuPIC is an open source project based on a theory of neocortex called Hierarchical Temporal Memory (HTM). Parts of HTM theory have been implemented, tested, and used in applications, and other parts of HTM theory are still being developed. Today the HTM code in NuPIC can be used to analyze streaming data. It learns the time-based patterns in data, predicts future values, and detects anomalies. NuPIC includes discussion groups on HTM theory, research on extending HTM, and source code for complete applications based on HTM. We welcome participation in all of these areas.
 eiot :
eiot : -
2016-09-24 14:00:32
Numenta is tackling one of the most important scientific challenges of all time: reverse engineering the neocortex. Studying how the brain works helps us understand the principles of intelligence and build machines that work on the same principles. We believe that understanding how the neocortex works is the fastest path to machine intelligence, and creating intelligent machines is important for the continued success of humankind.
We are at the beginning of a thrilling new era of computing that will unfold over the coming decades, and we invite you to learn about how our approach is helping to advance the state of brain theory and machine intelligence.
On this site, you’ll find information about our company. If you’re looking for technical resources, including details of our research, software implementations, and how to get started with our technology, visit our HTM open source community at http://numenta.org. eiot :
eiot : -
2016-09-23 02:02:52
С каких пор программы научились выдавать себя за людей? Каким образом понять, искусная ли перед нами обманка или по-настоящему сильный ИИ? Когда программа справится с машинным переводом или напишет свой первый роман? Сергей oulenspiegel Марков, автор материала «Играть на уровне бога: как ИИ научился побеждать человека», возвращается к теме умных машин в нашей новой нейронной статье.
 eiot :
eiot : -
2016-09-21 11:11:57
Deep reinforcement learning (DRL) brings the power of deep neural networks to bear on the generic task of trial-and-error learning, and its effectiveness has been convincingly demonstrated on tasks such as Atari video games and the game of Go. However, contemporary DRL systems inherit a number of shortcomings from the current generation of deep learning techniques. For example, they require very large datasets to work effectively, entailing that they are slow to learn even when such datasets are available. Moreover, they lack the ability to reason on an abstract level, which makes it difficult to implement high-level cognitive functions such as transfer learning, analogical reasoning, and hypothesis-based reasoning. Finally, their operation is largely opaque to humans, rendering them unsuitable for domains in which verifiability is important. In this paper, we propose an end-to-end reinforcement learning architecture comprising a neural back end and a symbolic front end with the potential to overcome each of these shortcomings. As proof-of-concept, we present a preliminary implementation of the architecture and apply it to several variants of a simple video game. We show that the resulting system -- though just a prototype -- learns effectively, and, by acquiring a set of symbolic rules that are easily comprehensible to humans, dramatically outperforms a conventional, fully neural DRL system on a stochastic variant of the game.
 eiot :
eiot : -
2016-09-08 05:02:26
Deep Learning
With massive amounts of computational power, machines can now recognize objects and translate speech in real time. Artificial intelligence is finally getting smart. eiot :
eiot : -
2016-09-07 04:08:39
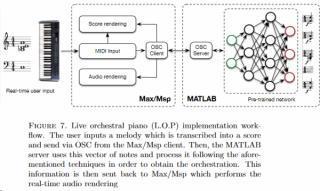
Сочинять-то музыку компьютеры давно умели. Вот, теперь будут сочинять и оркестровать. Впрочем, исполнять тоже, все эти работы по music rendering -- им несть числа. ИскИны должны быть культурными, разбираться в классике -- ходить в консерваторию (преподавать, композиторствовать, исполнять), в художественное училище (тоже явно не учиться).
 eiot :
eiot : -
2016-06-17 02:06:38
One of our core aspirations at OpenAI is to develop algorithms and techniques that endow computers with an understanding of our world.
 eiot :
eiot : -
2016-06-15 14:25:54
Американские нейрофизиологи сумели расшифровать данные томографии и реконструировать изображения лиц, о которых вспоминали подопытные. Об этом сообщает статья, опубликованная вJournal of Neuroscience.
 eiot :
eiot : -
2016-06-14 12:45:11
Этот цикл статей описывает волновую модель мозга, серьезно отличающуюся от традиционных моделей. Настоятельно рекомендую тем, кто только присоединился, начинать чтение с первой части.
 eiot :
eiot : -
2016-04-01 15:44:09
Исследовательский центр мультипроцессорных систем является подразделением Института программных систем им. А.К. Айламазяна РАН. Основные направления исследований центра: высокопроизводительные вычисления, программные системы для параллельных архитектур, аппаратные средства мультипроцессорных систем, суперкомпьютеры, GRID-технологии; технологии построения региональных компьютерных телекоммуникационных сетей; технологии построения сенсорных сетей; функциональное программирование, теория суперкомпиляции и метавычислений; исследование и разработка методов интеллектуального управления сложными динамическими объектами; работы по логическим и алгебраическим аспектам вычислений в условиях физических, ресурсных и функциональных ограничений.
 eiot :
eiot : -
2016-04-01 15:44:08
Основные направления научных исследований Лаборатории интеллектуального управления:
интеллектуальное управление сложными динамическими объектами;
образный анализ данных, когнитивная графика и методы отображения динамической информации;
интеллектуальные видео- и теле-измерительные информационные системы;
разрядно-параллельные геометрические процессоры для управления траекторным движением;
диагностика сложных технических систем (подсистем космических аппаратов, дизельной аппаратуры и др.);
защита компьютерных сетей от атак.eiot : -
2016-03-30 07:15:15
Виртуальная лаборатория занимается:
структурированием существующей и производством новой информации в области ИИ, агентов, разработки и моделирования ПО;
R&D, консалтингом, обучением в области model-driven development, domain-specific languages, multi-agent systems, AI;
созданием и моделированием как традиционного ПО, так и искусственных самостоятельных разумных существ, помогающих человеку и его бизнесу.eiot :